11. Januar 2026 15:55
Deluxe Connect 4 - Spieltheorie
11. Januar 2026 15:56
Quellenangabe
Die nachfolgenden Beschreibungen basieren auf dem Standardwerk zur künstlichen Intelligenz: „Artificial Intelligence – Modern Approach“ von Stuart Rusell und Peter Norvig
11. Januar 2026 15:57
Spieltheorie
In der Entwicklung von „Deluxe Connect 4“ befassen wir uns mit einer konkurrierenden Umgebung, in denen zwei Akteure (wovon einer menschlich ist) gegensätzliche Ziele haben, was zu adversarialen Suchproblemen führt. Anstatt sich mit dem Chaos zufälliger Scharmützel zu beschäftigen, ist dies ein Beispiel für Denkspiele wie Schach, Go, Mühle, Dame oder eben auch 4-Gewinnt.
Für KI Entwickler ist die vereinfachte Natur dieser Spiele ein klarer Vorteil: Der Zustand eines Spiels ist einfach zu repräsentieren und die Agenten/Spieler sind normalerweise auf eine kleine Anzahl von Aktionen beschränkt, deren Auswirkungen durch präzise Regeln definiert sind.
Aus Sicht des maschinellen Agenten gibt es mindestens drei Haltungen, die wir gegenüber diesen „Multiagentenumgebungen“ einnehmen können. Die erste Haltung, die bei einer sehr großen Anzahl von Agenten angebracht ist, besteht darin, sie im Ganzen als eine Ökonomie zu betrachten. Dadurch können wir zum Beispiel vorhersagen, dass eine steigende Nachfrage zu einem Preisanstieg führen wird, ohne die Aktion eines einzelnen Agenten vorhersagen zu müssen.
Zweitens könnten wir die gegnerischen Agenten lediglich als Teil der Umgebung ansehen - einen Teil, der die Umgebung nichtdeterministisch macht. Doch wenn wir die gegnerischen Agenten so modellieren wie beispielsweise das Wetter - also manchmal fällt Regen und manchmal nicht -, dann entgeht uns das Konzept, dass unsere Gegner aktiv versuchen, uns zu besiegen, während der Regen vermutlich keine derartigen Absichten hat.
Der dritte Ansatz ist die explizite Modellierung der gegnerischen Agenten mit den Techniken der adversarialen Spielbaumsuche - das eigentliche Thema dieses Abschnitts.
11. Januar 2026 15:59
Zuerst beginnen wir mit dem Versuch einen definierten optimalen Zug mit einem Algorithmus, der alle Stellungen bis zu einer bestimmten Suchtiefe bewertet, um diesen Zug zu finden: die Minimax-Suche.
Dabei wird zusätzlich das Konzept des Kürzens - Pruning - angewendet, die die Suche effizienter macht, indem Teile des Suchbaums ignoriert werden, die keinen Unterschied zum optimalen Zug machen.
Da wir dabei aber normalerweise nicht alle Zugkombinationen bis zum Ende des Spiels und einer Entbewertung durchspielen können, kommt der Nutzenfunktion einer Spielstellung eine große Funktion zu. Es gilt den Nutzen einer Stellung bis in die Vorschau einer bestimmten Anzahl von Zügen zu optimieren. Dies wird durch die Nutzenfunktion (Utility-Funktion) ausgedrückt, die bei der Entwicklung ein bestimmtes Spielverständnis voraussetzt.
11. Januar 2026 16:00
Der zweite Ansatz befasst sich mit heuristischen Evaluierungsfunktion, um von einem Zustand ausgehend mit vielen schnellen Simulationen des Spiels, für jeden zur Auswahl stehenden Zug abzuschätzen, wer gewinnen wird: Der Monte-Carlo-Tree-Search (Die Namensgebung ist dabei tatsächlich vom Casino des Monte Carlo abgeleitet).
Die Maximierung einer Nutzenfunktion zu einzelnen Stellungen spielt dabei keine Rolle, vielmehr werden viele zufällige Spiele bis zu einem Spielende durchgespielt und geprüft, wer gewonnen hat. Der Nutzen eines Zuges wird also mehr durch den statistischen durchschnittlichen Nutzen aus dem Ergebnis vieler Simulationen gezogen.
11. Januar 2026 16:01
Der dritte Ansatz befasst sich mit modernen neuronalen Netzen, die über einen Ansatz des Reinforcement Learnings trainiert wurden.
Das Reinforcement Learning (RL, Verstärkungslernen) ist dabei eine Trainingsmethode, bei dem ein Agent/Spieler mit der Spiel-Welt interagiert und periodisch Belohnungen (oder, in der Terminologie der Psychologie, Verstärkungen) erhält, die widerspiegeln, wie gut er sich schlägt. Beim 4-Gewinnt zum Beispiel ist die Belohnung 1 für einen Sieg, 0 für eine Niederlage und 0,5 für ein Remis.
Das Konzept der Belohnungen bei den verschiedenen Formen des Reinforcement Learning ist mehr oder weniger dasselbe: die erwartete Summe der Belohnungen zu maximieren. Reinforcement Learning ist dabei eine Weiterentwicklung eines Markov-Entscheidungsprozesses (MDPs), bei dem der Agent das MDP nicht als zu lösendes Problem übergeben bekommt; der Agent befindet sich vielmehr im MDP.
Er kennt möglicherweise weder das Transitionsmodell noch die Belohnungsfunktion und muss handeln, um mehr zu lernen. Stellen Sie sich vor, Sie spielen ein neues Spiel, dessen Regeln Sie nicht kennen. Nach etwa hundert Zügen sagt Ihnen der Schiedsrichter: „Sie haben verloren". Das ist Reinforcement Learning in Kürze.
In diesem Abschnitt werde ich nur grundsätzlich auf das Prinzip des Reinforcement Learning von neuronalen Netzen eingehen. In einem gesonderten Abschnitt werde ich auf
-
verschiedene Topologien von neuronalen Netzen (MLP - Multi Layer Perceptron, CNN - Convolutional Neural Network, RSN - Residual based spatial Network) und
-
verschiedene Trainingsmethoden (Reines Selflearning, PPO - Proximal Policy Optimization, Alpha Zero (inkl. MCTS), Curriculum Learning mit PPO) eingehen, die beim Reinforcement Learning sinnvoll angewendet werden können.
11. Januar 2026 16:03
Grundlagen zu Nullsummenspiele für zwei Spieler
Spieltheoretiker bezeichnen die in der KI am häufigsten untersuchten Spiele (wie Schach und Go, aber auch einfacher 4 Gewinnt) als deterministische Nullsummenspiele mit vollständiger Information für zwei Spieler, die sich mit den Spielzügen abwechseln.
„Vollständige Information" ist ein Synonym für „vollständig beobachtbar"' und „Nullsumme" bedeutet, dass das, was für den einen Spieler gut ist, für den anderen im gleichen Maß schlecht ist: Es gibt kein „Win-Win"- Ergebnis. Bei Spielen verwenden wir oft den Begriff Zug als Synonym für „Aktion" und Position als Synonym für „Zustand"
Wir werden die beiden Spieler MAX und MIN nennen, aus Gründen, die bald offensichtlich werden. MAX zieht zuerst, und dann ziehen die Spieler abwechselnd, bis das Spiel zu Ende ist. Am Ende des Spiels erhält der Gewinner Punkte und der Verlierer bekommt Strafpunkte.
Ein Spiel kann formal durch die folgenden Elemente definiert werden:
-
S0: der Anfangszustand, der angibt, wie das Spiel beim Start eingerichtet ist;
-
To-MOVE(s): der Spieler, der an der Reihe ist, im Zustand s zu ziehen;
-
ACTIONS(s): die Menge der zulässigen Züge im Zustand s;
-
RESULT(s, a): das Transitionsmodell, das den Zustand definiert, der sich aus Ausführung von Aktion a in Zustand s ergibt;
-
Is-TERMINAL(s): ein Endtest, der wahr (true) ist, wenn das Spiel beendet ist, und ansonsten falsch (false). Zustände, in denen das Spiel beendet ist, werden als Endzustände bezeichnet.
-
UTILITY(s, p): eine Nutzenfunktion (auch Zielfunktion oder Auszahlungsfunktion genannt), die den endgültigen numerischen Wert für den Spieler p definiert, wenn das Spiel im Endzustand s endet. Beim 4.Gewinnt ist das Ergebnis ein Sieg, ein Verlust oder ein Unentschieden mit den Werten 1, 0, oder 1/2.
Aus diesen Definitionen definieren der Anfangszustand, die ACTIONS-Funktion und die RESULT-Funktion den Zustandsraumgraphen - einen Graphen, bei dem die Ecken Zustände und die Kanten Züge sind und ein Zustand über mehrere Pfade erreicht werden kann. So können wir einen Suchbaum über einen Teil dieses Graphen legen, um den nächsten Zug zu bestimmen. Wir definieren den vollständigen Spielbaum als einen Suchbaum, der jeder Zugfolge bis zu einem Endzustand folgt. Der Spielbaum kann unendlich sein, wenn der Zustandsraum selbst unbegrenzt ist oder wenn die Spielregeln unendlich wiederholbare Positionen zulassen.
11. Januar 2026 16:07
Minimax: Optimale Entscheidungen in Spielen
MAX möchte nun eine Aktionsfolge finden, die zu einem Sieg führt, doch MIN hat ein Wörtchen mitzureden. Das heißt, die Strategie von MAX muss ein bedingter Plan sein - eine situative Strategie, die eine Reaktion auf jeden der möglichen Züge von MIN festlegt.
In Spielen, die einen binären Ausgang haben (gewinnen oder verlieren), könnten wir eine UND-ODER Suche verwenden, um den bedingten Plan zu erzeugen. Tatsächlich ist für solche Spiele die Definition einer Gewinnstrategie für das Spiel identisch mit der Definition einer Lösung für ein nichtdeterministisches Planungsproblem: In beiden Fällen muss das wünschenswerte Ergebnis garantiert werden, egal was die „andere Seite" tut.
Für Spiele mit mehreren Ausgangswerten benötigen wir einen etwas allgemeineren Algorithmus, der Minimax-Suche genannt wird.
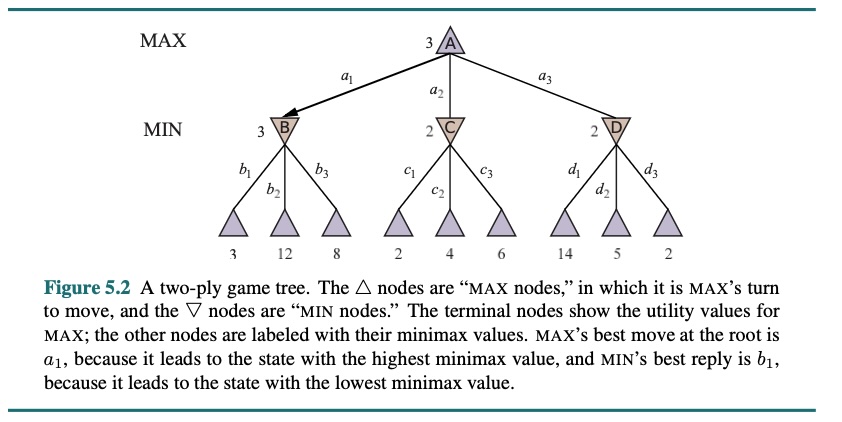
Betrachten wir das triviale Spiel in der nachfolgenden Abbildung. Die möglichen Züge für MAX am Wurzelknoten sind mit a1, a2 und a3 beschriftet. Die möglichen Antworten auf a1 für MIN sind mit b1, b2, b3 usw. Dieses spezielle Spiel endet nach je einem Zug von MAX und MIN. Die Nutzenwerte der Endzustände in diesem Spiel reichen von 2 bis 14.
11. Januar 2026 16:09
Bei einem Spielbaum kann die optimale Strategie bestimmt werden, indem der Minimax-Wert jedes Zustands im Baum berechnet wird, den wir als MINIMAX(s) schreiben. Der Minimax-Wert beschreibt den Nutzen (für MAX), in diesem Zustand zu sein, unter der Annahme, dass beide Spieler von dort bis zum Ende des Spiels optimal spielen.
Der Minimax-Wert eines Endzustands ist einfach sein Nutzenwert. In einem nicht terminalen Zustand bevorzug MAX es, zu einem Zustand mit maximalem Wert zu ziehen, wenn MAX an der Reihe ist und MIN bevorzugt einen Zustand mit minimalem Wert (d. h. minimaler Wert für MAX und somit maximaler Wert für MIN). Wir haben also:

11. Januar 2026 16:10
Wenden wir diese Definitionen nun auf den Spielbaum aus der vorherigen Abbildung an. Die Endknoten auf der untersten Ebene erhalten ihre Nutzenwerte von der UTILITY-Funktion des Spiels.
Der erste MIN-Knoten, beschriftet mit B, hat drei Nachfolgezustände mit den Werten 3, 12 und 8, also ist sein Minimax-Wert 3. Ähnlich haben die anderen beiden MIN-Knoten den Minimax-Wert 2. Der Wurzelknoten ist ein MAX-Knoten; seine Nachfolgezustände haben die Minimax-Werte 3, 2 und 2; er hat also einen Minimax-Wert von 3. Wir können auch die Minimax-Entscheidung am Wurzelknoten identifizieren: Aktion a, ist die optimale Wahl für MAX, da sie zu dem Zustand mit dem höchsten Minimax-Wert führt.
Diese Definition des optimalen Spiels für MAX setzt voraus, dass auch MIN optimal spielt. Was ist, wenn MIN nicht optimal spielt? Dann wird MAX mindestens so gut abschneiden wie gegen einen optimalen Spieler, möglicherweise sogar besser. Das bedeutet jedoch nicht, dass es immer am besten ist, den für MAX optimalen Zug zu spielen, wenn man einem suboptimalen Gegner gegenübersteht.
Betrachten wir eine Situation, in der das optimale Spiel beider Seiten zu einem Unentschieden führt, aber es gibt einen riskanten Zug für MAX, der zu einem Zustand führt, in dem es 10 mögliche Gegenzüge von MIN gibt, die alle vernünftig erscheinen, aber 9 davon sind ein Verlust für MIN und einer ist ein Verlust für MAX. Wenn MAX glaubt, dass MIN nicht genügend Rechenleistung besitzt, um den optimalen Zug zu entdecken, könnte MAX den riskanten Zug versuchen wollen, mit der Begründung, dass eine 9/10 Chance auf einen Sieg besser ist als ein sicheres Unentschieden.
11. Januar 2026 16:12
Der Minimax-Suchalgorithmus
Da wir nun in der Lage sind, MINIMAX(s) zu berechnen, können wir dies in einen Suchalgorithmus umwandeln, der den besten Zug für MAX findet, indem er alle Aktionen ausprobiert und diejenige auswählt, deren resultierender Zustand den höchsten MINIMAX-Wert hat.
Die nachfolgende Abbildung zeigt diesen Algorithmus. Es handelt sich um einen rekursiven Algorithmus, der bis zu den Blättern des Baums hinunterwandert und dann die Minimax-Werte durch den Baum hindurch sichert, während die Rekursion abgewickelt wird.

11. Januar 2026 16:12
In unserem einfachen Suchbaum zum Beispiel läuft der Algorithmus zunächst zu den drei Knoten unten links und wendet auf dies jeweils die UTILITY-Funktion an, mit der er feststellt, dass die Knoten die Werte 3, 12 bzw. 8 haben. Dann nimmt er das Minimum dieser Werte, also 3, und gibt es als gesicherten Wert von Knoten B zurück. Ein ähnlicher Prozess liefert die gesicherten Werte 2 für C und 2 für D. Schließlich nehmen wir das Maximum von 3, 2 und 2, um den gesicherten Wert 3 für den Wurzelknoten zu erhalten.
Der Minimax-Algorithmus führt eine vollständige Erkundung des Spielbaums in der Tiefe durch. Wenn die maximale Tiefe des Baums m ist und es an jedem Punkt b zulässige Züge gibt, dann ist die Zeitkomplexität des Minimax-Algorithmus O(b). Die exponentielle Komplexität macht MiNIMAX für komplexe Spiele unpraktisch; zum Beispiel hat Schach einen Verzweigungsfaktor von etwa 35 und das durchschnittliche Spiel hat eine Tiefe von etwa 80 Schichten - es ist nicht machbar, 35 hoch 80 ~ 10 hoch 123 Zustände zu suchen.
11. Januar 2026 16:15
Einschränkung durch Zugtiefe
Aber selbst ein viel einfacheres Spiel wie 4-Gewinnt hat etwa einen Spielbaum von 10 hoch 13 bis 10 hoch 14 Zugmöglichkeiten (nicht etwa 7 hoch 42, weil volle Spalten und vorherige Spielendstellungen, die Anzahl deutlich senken). Aber auch diese Anzahl der Zugmöglichkeiten ist unmöglich in kurzer Zeit zu berechnen.
Daher wird der Minimax-Algorithmus nur bis zu einer bestimmten Spieltiefe (=Zugtiefe) durchgespielt. Dadurch entstehen natürlich häufig Stellungen, die nicht final sind und mit Gewinn, Verlust oder Unentschieden enden. Auf diese Weise muss aber der UTILITY-Funktion weiteres Wissen über eine nicht finale Spielstellung mitgegeben werden. Die Spielstellung muss auf der tiefsten berechneten Zugebene mit einem Wert versehen werden, der angibt wie gut oder schlecht die Stellung ist. Über die rekursive Funktion wird das jeweilige Maximum bzw. Minimum (je nachdem wer am Zug ist) in die übergeordneten Knoten übertragen.
Für diese Form der UTILITY-Funktion (dann auch Evaluierungsfunktion genannt) ist demnach ein Spielwissen notwendig, dass am Beispiel 4-Gewinnt, zum Beispiel in einer Stellung die Bildung von 2er-Reihen, 3er-Reihen, Besetzung des Zentrums etc. mit jeweils einem (Teil-)Wert belohnt (eigener Spieler) oder bestraft (gegnerischer Spieler). Auf diese Weise entsteht normalerweise für jede Stellung ein Wert zwischen 0 bis 1 als Näherung an einen Gewinn (1) oder einen Verlust (0).
Diese Form der Minimax-Algorithmen bezeichnet man auch als heuristischen Minimax. Im Beispiel von „Deluxe Connect 4“ spielen 3 Minimax-Spieler mit, die entweder 3 Züge, 5 Züge oder 7 Züge tief denken. Man erkennt am ELO Ranking, das sich tieferes Denken positiv auswirkt und Minimax 7 z.B. besser abschneidet als Minimax 5 oder Minimax 3.
11. Januar 2026 16:16
Alpha-Beta-Pruning
Die Anzahl der Spielzustände ist exponentiell mit der Tiefe des Baums. Kein Algorithmus kann den Exponenten vollständig eliminieren, aber wir können ihn manchmal halbieren: wir können die korrekte Minimax-Entscheidung berechnen, ohne jeden Zustand zu untersuchen, indem wir große Teile des Baums kürzen, die nicht zum Endergebnis beitragen.
Die spezielle Technik, die wir hier untersuchen, heißt Alpha-Beta-Pruning. Betrachten wir wieder den Zwei-Schichten-Spielbaum aus der ersten Abbildung. Wir gehen die Berechnung der optimalen Entscheidung noch einmal durch, wobei wir dieses Mal beachten, was wir an jedem Punkt des Prozesses wissen. Die Schritte werden in der nachfolgenden Abbildung erklärt.

11. Januar 2026 16:17
Das Ergebnis ist, dass wir die Minimax-Entscheidung identifizieren können, ohne jemals zwei der Blattknoten auszuwerten.
Eine andere Betrachtungsweise ist eine Vereinfachung der Formel für MINIMAX. Die beiden unbewerteten Nachfolger des Knotens C in der Abbildung des Spielbaums hätten die Werte x und y. Dann ist der Wert des Wurzelknotens gegeben durch

11. Januar 2026 16:18
Mit anderen Worten: Der Wert der Wurzel und damit die Minimax-Entscheidung sind unabhängig von den Werten der Blätter x und y und können daher gekürzt werden.
Alpha-Beta-Pruning kann auf Bäume beliebiger Tiefe angewendet werden und es ist oft möglich, ganze Teilbäume zu kürzen und nicht nur Blätter.
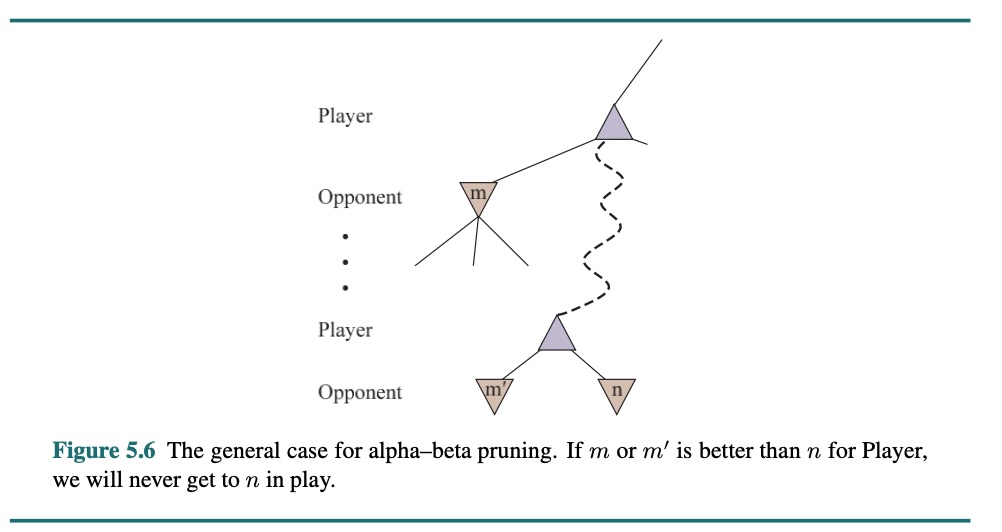
Das allgemeine Prinzip ist folgendes: Betrachten Sie einen Knoten n irgendwo im Baum (siehe nachfolgende Abbildung), zu dem sich „Spieler" hinbewegen könnte. Hat „Spieler" eine bessere Wahl, entweder auf der gleichen Ebene (z. B. m' in der Abbildung) oder an einem beliebigen Punkt weiter oben im Baum (z.B. m in Abbildung 5.6), dann wird er sich niemals zu n bewegen. Sobald wir also genug über n herausgefunden haben (indem wir einige seiner Nachkommen untersucht haben), um zu dieser Schlussfolgerung zu gelangen, können wir n kürzen.
11. Januar 2026 16:19
Denken Sie daran, dass die Minimax-Suche eine Tiefensuche ist - wir müssen also zu jedem Zeitpunkt nur die Knoten entlang eines einzigen Pfads im Baum betrachten. Alpha-Beta-Pruning hat seinen Namen von den beiden zusätzlichen Parametern in MAX-VALUE (state, a, B), die Schranken für die gesicherten Werte beschreiben, die irgendwo entlang des Pfads auftreten:
a = der Wert der besten Wahl (d.h. mit dem höchsten Wert), die wir bisher an jedem Auswahlpunkt entlang des Pfads für MAX ermittelt haben. Merke: a = „mindestens"
ß = der Wert der besten Wahl (d.h. mit dem niedrigsten Wert), die wir bisher an jedem Auswahlpunkt entlang des Pfads für MIN ermittelt haben. Merke: B = „höchstens"
Die Alpha-Beta-Suche aktualisiert die Werte von a und ß im weiteren Verlauf und kürzt die verbleibenden Zweige an einem Knoten (d.h. beendet den rekursiven Aufruf), sobald herausgefunden wurde, dass der Wert des aktuellen Knotens schlechter ist als der aktuelle a- oder ß-Wert für MAX bzw. MIN.
Der vollständige Algorithmus ist in der nachfolgenden Abbildung dargestellt.

11. Januar 2026 16:20
Monte-Carlo-Tree-Search
Spiele wie Go oder Schach veranschaulichen die zwei großen Schwächen der heuristischen Minimax-Baumsuche (inkl. Alpha-Beta-Pruning): Erstens hat z.B. Go einen Verzweigungsfaktor, der bei 361 beginnt, was bedeutet, dass die Minimax-Suche auf nur 4 oder 5 Zügen begrenzt wäre.
Zweitens ist es schwierig, eine gute Evaluierungsfunktion z.B. für Go zu definieren, da der Materialwert kein starker Indikator ist und die meisten Stellungen bis zum Endspiel im Fluss sind. Als Antwort auf diese beiden Herausforderungen haben moderne Go-Programme die Alpha-Beta-Suche aufgegeben und verwenden stattdessen eine alternative Strategie, die Monte-Carlo-Suche (Monte Carlo Tree Search, MCTS) genannt wird (Der Name ist wirklich vom Casino de Monte-Carlo abgeleitet).
Die grundlegende MCTS-Strategie verwendet keine heuristische Evaluierungsfunktion. Stattdessen wird der Wert eines Zustands als durchschnittlicher Nutzen über eine Anzahl von Simulationen kompletter Spiele, die mit diesem Zustand beginnen, geschätzt. Bei einer Simulation (auch Playout oder Rollout genannt) werden zuerst Züge für einen Spieler und dann für den anderen Spieler ausgewählt, was so lange wiederholt wird, bis eine Endposition erreicht ist. An diesem Punkt bestimmen die Spielregeln (nichtfehlbare Heuristiken), wer gewonnen oder verloren hat und mit welchem Ergebnis. Für Spiele, bei denen die einzigen Ergebnisse ein Sieg oder eine Niederlage sind, ist „durchschnittlicher Nutzen" dasselbe wie „Gewinnprozentsatz".
Wie wählen wir aus, welche Züge wir während des Playout machen? Wenn wir einfach zufällig wählen, dann erhalten wir nach mehreren Simulationen eine Antwort auf die Frage „Was ist der beste Zug, wenn beide Spieler zufällig spielen?" Für einige einfache Spiele ist die Antwort tatsächlich dieselbe wie auf die Frage „Was ist der beste Zug, wenn beide Spieler gut spielen?", doch für die meisten Spiele trifft das nicht zu.
Um nützliche Informationen aus dem Playout zu erhalten, benötigen wir eine Playout-Strategie, die die Züge so lenkt, dass es gute Züge werden. Für Go und andere Spiele wurden Playout-Strategien erfolgreich mithilfe von neuronalen Netzen durch Selbstspiel gelernt. Manchmal werden auch spielspezifische Heuristiken verwendet, wie z. B. „Schlagzüge berücksichtigen" beim Schach oder „das Eckfeld einnehmen" bei Othello.
Ausgehend von einer gegebenen Playout-Strategie müssen wir als Nächstes zwei Dinge entscheiden: Von welchen Stellungen aus starten wir die Playouts und wie viele Playouts weisen wir jeder Stellung zu?
Die einfachste Antwort, die als reine Monte-Carlo-Suche bezeichnet wird, besteht darin, N Simulationen ausgehend vom aktuellen Zustand des Spiels durchzuführen und zu verfolgen, welcher der möglichen Züge von der aktuellen Position aus den höchsten Gewinnprozentsatz aufweist.
Für einige stochastische Spiele nähert sich dies mit wachsendem N einem optimalen Spiel, doch für die meisten Spiele reicht es nicht aus - wir benötigen eine Auswahlstrategie, die die Rechenressourcen selektiv auf die wichtigen Teile des Spielbaums konzentriert. Es müssen zwei Faktoren ausbalanciert werden: Exploration von Zuständen, die nur wenige Playouts hatten, und Exploitation von Zuständen, die in vergangenen Playouts gut abgeschnitten haben, um eine genauere Schätzung ihres Werts zu erhalten.
11. Januar 2026 16:22
Grundlegende Logik von MCTS
Die Monte-Carlo-Baumsuche verwaltet dazu einen Suchbaum, der bei jeder Iteration durch Anwenden der folgenden vier Schritte wächst:
11. Januar 2026 16:22
-
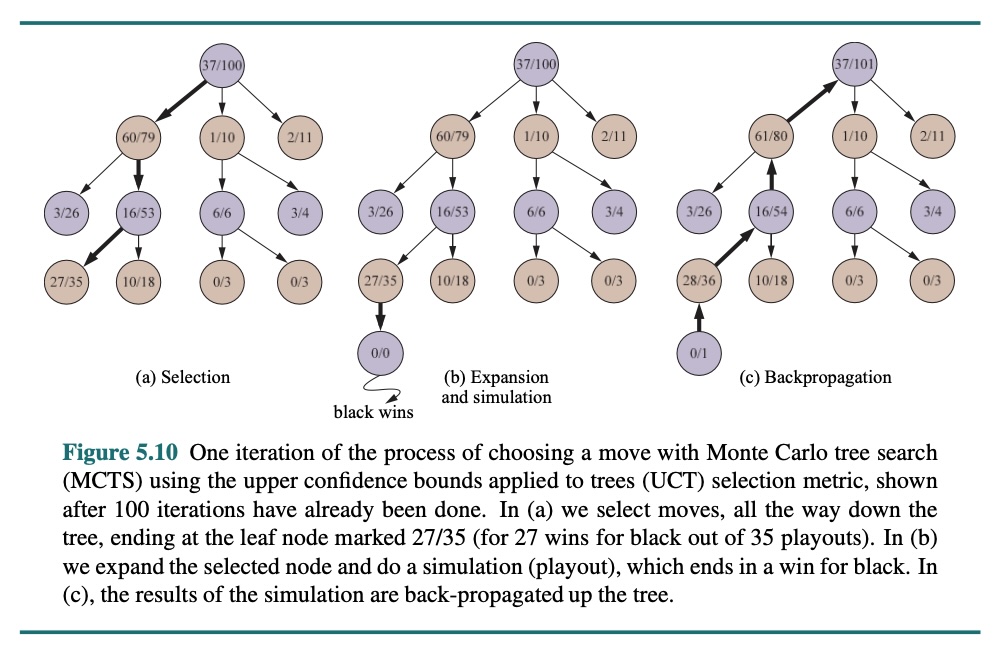
Selektion: Beginnend an der Wurzel des Suchbaums wählen wir einen Zug (anhand der Auswahlstrategie), der zu einem Nachfolgerknoten führt, und wiederholen dann diesen Prozess, durch den wir uns den Baum hinunter bis zu einem Blatt bewegen. In der obigen Abbildung zeigt (a) einen Suchbaum, bei dem die Wurzel einen Zustand repräsentiert, in dem Weiß gerade gezogen hat und Weiß 37 der 100 bisher durchgeführten Playouts gewonnen hat. Der dicke Pfeil zeigt die Selektion eines Zugs durch Schwarz, der zu einem Knotenpunkt führt, an dem Schwarz 60/79 Playouts gewonnen hat. Dies ist der beste Gewinnprozentsatz unter den drei Zügen, also ist die Auswahl dieses Zugs ein Beispiel für Exploitation. Aber es wäre auch denkbar gewesen, den 2/11-Knoten zur Exploration auszuwählen. Denn mit nur 11 Playouts hat der Knoten immer noch eine hohe Unsicherheit in seiner Bewertung und könnte letzten Endes der beste sein, wenn wir mehr Informationen über ihn gewinnen. Die Selektion wird bis zum Blattknoten mit der Bezeichnung 27/35 fortgesetzt.
-
Expansion: Wir erweitern den Suchbaum, indem wir ein neues Kind des ausgewählten Knotens erzeugen; In der Abbildung zeigt (b) den neuen Knoten, der mit 0/0 markiert ist. (Einige Versionen erzeugen in diesem Schritt mehr als ein Kind.)
-
Simulation: Wir führen ein Playout des neu erzeugten Kindknotens aus und wählen dabei Züge für beide Spieler gemäß der Playout-Strategie. Diese Züge werden nicht im Suchbaum aufgezeichnet. In der Abbildung führt die Simulation zu einem Sieg für Schwarz.
-
Rückwärtspropagation: Wir verwenden nun das Ergebnis der Simulation, um alle Knoten des Suchbaums zu aktualisieren, die bis zur Wurzel gehen. Da Schwarz das Playout gewonnen hat, werden die schwarzen Knoten sowohl in der Anzahl der Siege als auch in der Anzahl der Playouts inkrementiert, also wird 27/35 zu 28/36 und 60/79 zu 61/80. Da Weiß verloren hat, werden die weißen Knoten nur in der Anzahl der Playouts inkrementiert, sodass 16/53 zu 16/54 und die Wurzel 37/100 zu 37/101 wird.
Wir wiederholen diese vier Schritte entweder für eine festgelegte Anzahl von Iterationen oder bis die vorgegebene Zeit abgelaufen ist und geben dann den Zug mit der höchsten Anzahl von Playouts zurück.
11. Januar 2026 16:24
Wie sieht nun eine effektive Auswahlstrategie aus?
Eine sehr effektive Auswahlstrategie heißt „Obere Konfidenzgrenzen auf Bäume anwenden" (Upper Confidence Bounds applied to Trees, UCT).
Diese Strategie erstellt eine Rangfolge aller möglichen Züge basierend auf einer Obere-Konfidenzgrenze-Formel genannt UCB1.
Für einen Knoten n lautet die Formel:
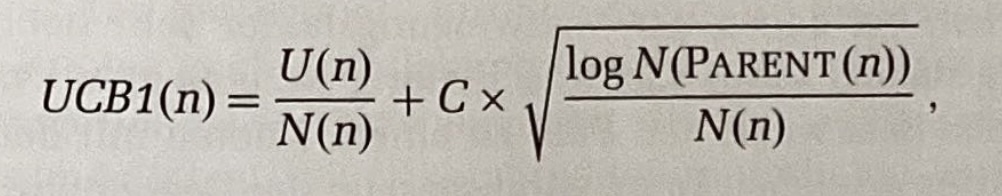
11. Januar 2026 16:24
wobei
U(n) der Gesamtnutzen aller Playouts ist, die über den Knoten n gehen,
N(n) die Anzahl der Playouts über den Knoten n angibt und
PARENT(n) für den Elternknoten von n im Baum steht.
Folglich ist U(n)/N(n) der Exploitationsterm, das heißt der durchschnittliche Nutzen von n.
Der Term mit der Quadratwurzel ist der Explorationsterm: Im Nenner steht die Anzahl N(n), was bedeutet, dass der Term umso höher ist, je weniger ein Knoten exploriert wurde. Im Zähler steht der Logarithmus der Anzahl der Explorationen vom Elternknoten von n.
Wenn wir also n x-mal auswählen (wobei x nicht null sein darf), geht der Explorationsterm bei zunehmender Höhe von x gegen null, und am Ende erfolgen die Playouts über den Knoten mit dem höchsten Durchschnittsnutzen.
C ist eine Konstante, die Exploration und Exploitation ausgleicht. Es gibt das theoretische Argument, dass C die Wurzel aus 2 (ca. 1,41) sein sollte, aber in der Praxis probieren Spieleprogrammierer mehrere Werte für C aus und wählen denjenigen, der am besten abschneidet. (Einige Programme verwenden leicht abweichende Formeln. Zum Beispiel fügt ALPHAZERO einen Term für die Zugwahrscheinlichkeit hinzu, der von einem neuronalen Netz berechnet wird, das mithile von Selbstspiel trainiert wurde.) Mit C = 1,4 hat der Knoten 60/79 in der Abbildung den höchsten UCB1-Wert, mit C = 1,5 wäre es jedoch der Knoten 2/11.
In Deluxe Connect 4 wird für C die Wurzel aus 2 angewendet und hat gute Resultate erzielt.
11. Januar 2026 16:26
UCT-MCTS-Algorithmus
Die nachfolgende Abbildung zeigt den Pseudocode des vollständigen UCT-MCTS-Algorithmus.
Wenn die Iterationen enden, wird der Zug mit der höchsten Anzahl von Playouts zurückgegeben. Man könnte meinen, dass es besser wäre, den Knoten mit dem höchsten durchschnittlichen Nutzen zurückzugeben, aber die Idee ist, dass ein Knoten mit 65/100 Siegen besser ist als einer mit 2/3 Siegen, weil Letzterer eine größere Unsicherheit aufweist. In jedem Fall stellt die UCB1-Forme sicher, dass der Knoten mit den meisten Playouts fast immer der Knoten mit dem prozentual meisten Siegen ist, da dieser vom Auswahlprozess verstärkt begünstigt wird, je höher die Anzahl der Playouts ist.

11. Januar 2026 16:26
Heuristischer Minimax (inkl. Alpha-Beta-Pruning) versus UCT-Monte-Carlo-Tree-Search
Die Zeit für die Berechnung eines Playouts ist bei MCTS nicht exponentiell, sondern linear zur Tiefe des Spielbaums, da an jedem Entscheidungspunkt nur ein Zug ausgeführt wird. Das gibt uns viel Zeit für eine Reihe weiterer Playouts.
Ein Beispiel: Betrachten Sie ein Spiel mit dem Verzweigungsfaktor 32, bei dem das durchschnittliche Spiel über 100 Schichten geht. Wenn wir genug Rechenleistung haben, um eine Milliarde Spielzustände zu berücksichtigen, bevor wir einen Zug machen müssen, dann kann Minimax 6 Schichten tief suchen, Alpha-Beta mit perfekter Zugreihenfolge kommt auf 12 Schichten und die Monte-Carlo-Suche schafft 10 Millionen Playouts.
Welcher Ansatz ist nun der bessere? Das hängt von der Genauigkeit der heuristischen Funktion gegenüber den Auswahl- und Playout-Strategien ab.
In Deluxe Connect 4 werden die MCTS-Spieler nicht nach Anzahl von Playouts, sondern in Sekunden der Bedenkzeit. Auf einem Macbook schafft ein MCTS mit 10 Sekunden fast 100.000 Spiele! Die allgemein auf meinem Server zur Verfügung gestellte Version wird deutlich weniger Spiele schaffen, weil der zugrundeliegende Rechner viel schwächer ist.
Die gängige Meinung ist, dass die Monte-Carlo-Suche einen Vorteil gegenüber Minimax (mit Alpha-Beta-Pruning) bei Spielen wie Go hat, bei denen der Verzweigungsfaktor sehr hoch ist (und Minimax daher nicht tief genug suchen kann) oder es schwierig ist, eine gute Evaluierungsfunktion zu definieren. Denn Minimax wählt den Pfad zu einem Knoten mit dem höchsten Wert, den die Evaluierungsfunktion erreichen kann, vorausgesetzt der Gegner wird versuchen, den Wert zu minimieren. Wenn also die Evaluierungsfunktion ungenau ist, dann ist auch Minimax ungenau. Eine Fehlberechnung auf einem einzelnen Knoten kann dazu führen, dass Minimax fälschlicherweise einen Pfad zu diesem Knoten wählt (oder vermeidet).
Die Monte-Carlo Suche beruht jedoch auf der Menge vieler Playouts und ist daher nicht so anfällig für einen einzelnen Fehler. Wenn allerdings nur wenig Zeit für die Erstellung der Playouts zur Verfügung gestellt wird, kann es passieren, dass die Anzahl der Playouts nicht aussagekräftig genug sind oder einzelne Knoten zu selten besucht wurden. In diesen Fällen sieht kann es passieren, dass MCTS direkt patzt, weil es offensichtliche Züge nicht gefunden hat.
In der Entwicklung der maschinellen Spieler stellte sich auch bei Deluxe Connect 4 eine klare Überlegenheit von Monte Carlo Tree Search heraus. Wobei doch zu denken bleibt, dass ein MTCS mit 7 Sekunden Bedenkzeit wieder schlechter abschneidet als ein Minimax mit einer Zugtiefe von 7 Zügen. Klarer Sieger blieb aber ein Monte Carlo Tree Search, der sich 10 Sekunden für jeden Zug Bedenkzeit nehmen durfte.
Es gibt auch Strategien, die Minimax (mit Alpha-Beta-Pruning) und UCT-MCTS miteinander kombinieren. Zum Beispiel in dem zuerst mit einer Zugtiefe von 3 - 4 Schritten eine heuristische Minimax Strategie ausgeführt wird und darauf für die Auswahl der besten Züge der Monte-Carlo-Tree-Search eine Tiefenanalyse durchführen darf. Typischstes Beispiel dafür war bei Schachcomputern die Mephisto Reihe in der Mitte der 80er Jahre. Sie waren als gängige Schachcomputer im Consumer-Markt erhältlich und hatten für die damalige Zeit in den höchsten Spielstufen eine kaum zu schlagender Spielstärke.
11. Januar 2026 16:29
Grundlage zu Neuronalen Netzen
Nachfolgend springen wir direkt in die Welt der neuronalen Netze, die - einfach ausgedrückt - versucht, die menschliche Art des Lernens in unserem Gehirn nachzubilden.
Ein Neuron - ähnlich einer Synapse in unserem Gehirn - erzeugt dabei auf Basis eines Eingangswertes über einen Multiplikator einen Ausgangswert. Dies geschieht aber nur, wenn der Eingangswert einen bestimmten Schwellwert überschritten hat.
Mathematisch kann man dies durch die einfache Gleichung y = m*x für {x > s; ansonsten 0} zum Ausdruck bringen, wobei s = Schwellwert und m für den Multiplikation, der sich immer im Bereich zwischen 0 < m < 1 befindet.
Der Eingangswert x setzt sich nun wiederum aus dem Ergebnis von vielen anderen Neuronen zusammen, mit denen ein Neuron im Vorfeld verknüpft ist. Wiederum der Ausgangswert y wird an viele andere Neuronen weitergeleitet, mit denen das Neuron im Nachgang verknüpft ist. Auf diese Weise entsteht ein ganzen Neuronen-Netz.
Beim Trainieren eines neuronalen Netzes mit Trainingsmaterial werden mit jedem Versuch/Durchlauf die Werte m und s aller Neuronen verändert. Sind genügend Neuronen vorhanden, können auf diese Weise zahlreiche Informationen miteinander verknüpft (assoziiert), also in eine Beziehung zueinander gesetzt werden.
Heute große LLM bestehen aus mehreren 100 Milliarden Neuronen (!) und wurden mit Billionen von Trainingsdaten trainiert. Auf diese Weise entsteht ein riesiges assoziatives Beziehungsnetz zwischen vielen verschiedenen Tokens.
Aber auch für unsere viel kleineren Aufgaben zum Spielen von „4-gewinnt“ (bei dem übrigens ChatGPT kläglich scheitert, weil es dafür nicht trainiert wurde), kann man neuronale Netze nutzen. Dies müssen auch bei weitem nicht so groß sein, und umfassen kaum mehr als 1 bis 3 MB. Dabei kann man verschiedene Netzwerk-Topologien unterscheiden, die ich hier nur kurz anreißen will, und in einem separaten Abschnitt im Detail erläutern möchte.
11. Januar 2026 16:30
In der Spieltheorie für Nullensummenspiele haben sich folgende Netzwerktopologien bewährt:
-
MLP - Multi-Layer-Perceptrons: Die ist die klassische Netzstruktur mit vielen Neuronen nebeneinander (in einem Layer), die alle mit Neuronen in einer nachfolgende Reihe (Layer) verbunden sind usw. Das einfache Perceptron entspricht dabei der obigen Erläuterung eines Neurons Ein MLP gehört zu den Feed-Forward-Netzwerken, weil es ausgehend von Eingangsneuronen, über verschiedene Layer immer in einer Richtung zu Ausgangsneuronen führt
-
CNN - Convolutional Neural Network CNN: werden im Grunde häufig bei der Bildbearbeitung verwendet und faltet Informationen einzelner Bits zusammen und übergibt diese Informationen an den Assoziativ-Speicher des neuronalen Netzes. Folgende Idee steckt dahinter: Wenn man einen Bildpunkt links oben in einem Bild nimmt, dann werden die Punkte direkt daneben eine viel ähnlichere Beziehung zu diesem Punkt haben, als z.B. ein Bildpunkt rechts unten. Daher kann man den Bildpunkt mit seinem Nebenpunkten zusammenfalten und damit das Datenvolumen deutlich kürzen und stärker auf wesentliche Beziehungen eingehen. Diese in der Bildbearbeitung bewährte Technik kann man aber auch auf Spielsituationen auf einem Spielbrett (z.B. von Schach, Go oder 4-gewinnt) anwenden, in dem ich die Figuren- oder Spielsteingruppierung einzelner Felder zu einem „Metafeld“ zusammenfassen. So werden z.B. bei 4 gewinnt zu Beginn eines Spiels die leeren Spielfelder in den oberen Reihen direkt zu einem großen leeren Feld zusammengefasst. Der Blick kann sich also auf das Wesentliche in den unteren Reihen konzentrieren. Ansonsten gehören CNN auch zu den Feed-Forward-Netzwerken ähnlich der MLP-Netze.
-
RSN - Residual based spatial Network: Der Begriff Residual drückst bereits aus, dass es bei dieser Netzwerk Topologie zu (mehrstufigen) Rückkopplungen kommen kann, die bestimmte Bereiche des Assoziativ-Speichern verstärken kann und damit auf ausschlaggebende Aspekte verstärken kann. Der Begriff Spatial bedeutet, dass dem Netzwerk zusätzliche Neuronen-Layer zur Verfügung gestellt werden, die bestimmte räumliche Strukturen abbilden sollen. Im Falle von 4 Gewinnt werden gezielt räumliche Neuronen gebildet, die 4-Felder-Verkettungen in waagerechter, senkrechter und diagonaler Struktur abbilden sollen. Diese Topologien sind je Spiel sehr speziell eingerichtet und erfordern vom Entwickler gezieltes Spielverständnis, was der Idee des Reinforcement Learning eigentlich entgegenläuft.
11. Januar 2026 16:31
Das normale Training eines neuronalen Netzes besteht aus einem sogenannten „überwachten Training“, bei dem sehr sehr viele Trainingsbeispiele mit Eingangswerten und korrekten Ausgangswerten dem Netz zur Verfügung gestellt werden.
Das Netz überprüft nun beim Durchlauf durch seine Neuronen das Ergebnis der Trainingsdaten und versucht auf Basis des Vergleichs zwischen den richtigen Ausgangswerten und den erzielten Ergebniswerten die Parameter des Netzes (also aller m und s - Parameter eines jeden Neurons) in Summe besser an die Ausgangswerte heranzukommen. Diese Trainingsläufe werden häufig millionenfach wiederholt, bis die Parameter so eingestellt sind, dass die Ausgangswerte gut getroffen werden.
Was ist aber nun der so große Vorteil eines auf dieser Weise trainierten neuronalen Netzes? Schließlich könnte ich die Daten auch schlicht in der einer Datenbank speichern.
Hier kommt nun das Generative bzw. die Fähigkeit der Assoziation eines neuronalen Netzes zum Tragen. Während man aus einer Datenbank nur Daten ausgeben kann, die man vorher dort gespeichert hat (und ggf. beliebig miteinander kombiniert), kann ein neuroyales Netz auf Basis seines Assoziativ-Speichers für neue Situation den Wert ausgeben, der in Bezug auf seine gespeicherten Assoziationen am besten passt. Es generiert also bei neuen Eingabedaten auch neue Ausgangsdaten. Je besser das System trainiert wurde, um so besser wird dann das generierte Ergebnis sein.
Kommen wir nun aber zum Reinforcement Learning von neuronalen Netzen, mit dem ein anderer Trainingsansatz verfolgt wird.
11. Januar 2026 16:33
Reinforcement Learning: Aus Belohnungen lernen
Betrachten wir zum Beispiel das Problem, Schachspielen zu lernen. Dabei stellen wir uns vor, dass wir unser neuronales Netz mit einem überwachten Training behandeln. Die Funktion des schachspielenden Agenten nimmt als Eingabe eine Brettposition entgegen und gibt einen Zug zurück, also trainieren wir diese Funktion, indem wir Beispiele von Schachpositionen liefern, die jeweils mit dem richtigen Zug beschriftet sind. Zum Glück haben wir Datenbanken mit mehreren Millionen Großmeisterpartien zur Verfügung, jede eine Sequenz von Positionen und Zügen.
Es wird davon ausgegangen, dass die Züge des Gewinners bis auf wenige Ausnahmen gut, wenn auch nicht immer perfekt sind. Wir haben also eine vielversprechende Trainingsmenge. Das Problem ist, dass es relativ wenige Beispiele gibt (etwa 10 hoch 8), verglichen mit dem Raum aller möglichen Schachstellungen (etwa 10 hoch 40). In einer neuen Partie stößt man schnell auf Stellungen, die sich deutlich von denen in der Datenbank unterscheiden, und die trainierte Agentenfunktion wird wahrscheinlich kläglich scheitern nicht zuletzt, weil sie keine Ahnung hat, was sie mit ihren Zügen erreichen soll (Schachmatt) oder sogar welche Auswirkungen die Züge auf die Positionen der Figuren haben. Und natürlich ist Schach nur ein winziger Teil der realen Welt. Für realistischere Probleme bräuchten wir viel umfangreichere Großmeister-Datenbanken, und die gibt es einfach nicht. In diesem Fall wird der Assoziativ-Speicher einfach immer zu klein sein, um gute neue Ausgangswerte generieren zu können.
Eine Alternative ist das Reinforcement Learning (RL, Verstärkungslernen), bei dem ein Agent mit der Welt interagiert und periodisch Belohnungen (oder, in der Terminologie der Psychologie, Verstärkungen) erhält, die widerspiegeln, wie gut er sich schlägt. Beim Schach zum Beispiel ist die Belohnung 1 für einen Sieg, 0 für eine Niederlage und 0,5 für ein Remis. Das Konzept der Belohnungen bei den verschiedenen Formen des Reinforcement Learning ist mehr oder weniger dasselbe: die erwartete Summe der Belohnungen zu maximieren. Reinforcement Learning ist dabei eine Weiterentwicklung eines Markov-Entscheidungsprozesses (MDPs), bei dem der Agent das MDP nicht als zu lösendes Problem übergeben bekommt; der Agent befindet sich vielmehr im MDP. Er kennt möglicherweise weder das Transitionsmodell noch die Belohnungsfunktion und muss handeln, um mehr zu lernen. Stellen Sie sich vor, Sie spielen ein neues Spiel, dessen Regeln Sie nicht kennen.
Nach etwa hundert Zügen sagt Ihnen der Schiedsrichter: „Sie haben verloren". Das ist Reinforcement Learning in Kürze.
11. Januar 2026 16:36
Aus der Sicht als Entwickler von KI-Systemen ist es in der Regel viel einfacher, dem Agenten ein Belohnungssignal zu senden, anstatt mit Labeln versehene Beispiele davon zu liefern, wie er sich verhalten soll.
Erstens ist die Belohnungsfunktion oft (wie wir beim Schach gesehen haben) sehr kurz und einfach zu spezifizieren: Es sind nur ein paar Zeilen Code erforderlich, um den Schach-Agenten mitzuteilen, ob er das Spiel gewonnen oder verloren hat, oder um dem Rennfahrer-Agenten mitzuteilen, dass er das Rennen gewonnen oder verloren hat bzw. einen Unfall hatte.
Zweitens müssen wir keine Experten sein, die in der Lage sind, in jeder Situation die richtige Aktion zu liefern, wie es der Fall wäre, wenn wir versuchen würden, überwachtes Lernen anzuwenden.
Es stellt sich jedoch heraus, dass ein wenig Fachwissen beim Reinforcement Learning einen großen Unterschied machen kann. Die beiden Beispiele im vorangegangenen Absatz - die Gewonnen/Verloren-Belohnungen für Schach und Autorennen - sind das, was wir spärliche Belohnungen nennen, weil der Agent in der groben Mehrheit der Zustände überhaupt kein informatives Belohnungssignal erhält.
In Spielen wie Tennis und Cricket können wir leicht zusätzliche Belohnungen für jeden gewonnenen Punkt oder für jeden erzielten Run bereitstellen. Bei Autorennen könnten wir den Agenten für das Vorankommen auf der Strecke in der richtigen Richtung belohnen. Beim Krabbelnlernen ist jede Vorwärtsbewegung eine Leistung.
Diese Zwischenbelohnungen machen das Lernen viel einfacher.
Solange wir dem Agenten das richtige Belohnungssignal geben können, bietet Reinforcement Learning eine sehr allgemeine Möglichkeit, KI-Systeme zu erstellen. Dies gilt insbesondere für simulierte Umgebungen, wo es keinen Mangel an Möglichkeiten gibt, Erfahrungen zu sammeln. Das Hinzufügen von Deep Learning als Werkzeug in RL-Systemen hat zusätzlich neue Anwendungen ermöglicht, darunter das Erlernen von Atari-Videospielen aus rohen visuellen Eingaben, die Steuerung von Robotern und das Pokerspielen.
11. Januar 2026 16:38
Es wurden buchstäblich Hunderte von verschiedenen RL-Algorithmen entwickelt und viele von ihnen können als Werkzeuge eine breite Palette von Lernmethoden verwenden. In diesem Abschnitt gehe ich auf die Grundideen ein und vermittle einen groben Überblick, um einen Eindruck zu vermitteln.
Für das Training von „Deluxe Connect 4“ wurden folgenden Trainingsmethoden getestet:
-
Reines Self learning: Das System lernt, indem es gegen sich selbst spielt und nur aus Gewinnen/Verlusten seine Strategie verbessert.
-
PPO - Proximal Policy Optimization: Es spielen quasi zwei ähnliche Netze gegen einander PPO ist ein Reinforcement-Learning-Algorithmus, der eine Policy π(a|s) trainiert. Das System spielt gegen eine festgelegte Policy, die nicht notwendigerweise die eigene ist, z. B. die aktuelle Version des Agenten oder eine ältere Version. Die Policy wird nur schrittweise angepasst. Auf diese Weise werden die Erkenntnisse vieler Spielsituationen zusammengefasst und nur akzentuiert angepasst. Das Ergebnis ist nicht das Player Netz, sondern die letztlich erzielte angepasste policy.
-
Alpha Zero (inkl. MCTS): Ein Verfahren, das PPO-Ansatz mit einer neuronalen Netzbewertung und Monte-Carlo Tree Search (MCTS) kombiniert, um Züge zu planen und daraus zu lernen. Es kombiniert die analytischen Fähigkeiten von MCTS mit dem Assoziativ-Speicher der neuronalen Netze. Ein sehr aufwendiges und performance kritisches Verfahren, was aber hervorragende Ergebnisse erzielen kann.
-
Curriculum Learning mit PPO): PPO wird mit einem Lehrplan (Curriculum) trainiert: erst einfache Aufgaben, dann schrittweise schwierigere. Auf diese Weise kann man den Assoziativ-Speicher besser anleiten, Schritt für Schritt Beziehungen aufzubauen.