KI Sauklaue - Trainieren
Raimund
26. August 2025 13:37
Trainieren eines KI Sauklaue-Modells mit Deiner Handschrift
Wie wird ein KI Sauklaue Modell trainiert?
Das Projekt KI Sauklaue basiert auf einem vortrainierten TrOCR-System von Microsoft. Dieses System ist bereits grundsätzlich in der Lage (gut leserliche) Handschriften zu erkennen.
Damit das TrOCR-System mit Deiner Handschrift, egal wie schön oder schludrig geschrieben, zurechtkommt, muss es mit Deiner Handschrift vertraut gemacht werden. Diesen Prozess nennt man das Trainieren eines TrOCR-Systems.
Für dieses Training werden viele Trainingsdaten von Deiner Handschrift benötigt, die als Wortbilder (als einem Foto eines Wortes Deiner Handschrift) mit einem Label (also der digitalen Schrift des Wortes) für das System zur Verfügung stehen.
Damit ein TrOCR-Modell mit einer neuen individuellen Handschrift zu recht kommt, braucht es etwa 8.000 – 15.000 dieser Wortbilder. Das klingt sehr viel und nach einer unendlichen Arbeit so viele Worte zu fotografieren und eine Beschreibung mit dem Begriff mitzugeben.
Aber so schlimm ist es zum Glück nicht.
Wie werden die Trainingsdaten für KI Sauklaue erzeugt?
Das Projekt KI Sauklaue unterstützt Dich dabei daher tatkräftig, in dem es ganze Textseiten von Dir entgegennimmt, den eigentlichen Text extrahiert und verstärkt und diesen Text dann in Textzeilen und Wortbilder automatisch untergliedert. Auch das Labeln der Wortbilder erfolgt dann automatisch, wenn Du zur Textseite den gesamten Text zeilengerecht erfasst hast.
In meinem Fall hat es lediglich 150 DIN A5-Seiten meines Tagebuchs benötigt, um daraus über 12.000 Wortbilder zu kreieren und damit mein „Modell Tagebuch“ zu erzeugen.
Hier ist eine Übersicht über den gesamten Prozess zur Gewinnung von Trainingsdaten:

Raimund
26. August 2025 13:39
In der ersten Stufe wird ein Foto der Tagebuch-Seite gemacht und der zugehörige Text erfasst:
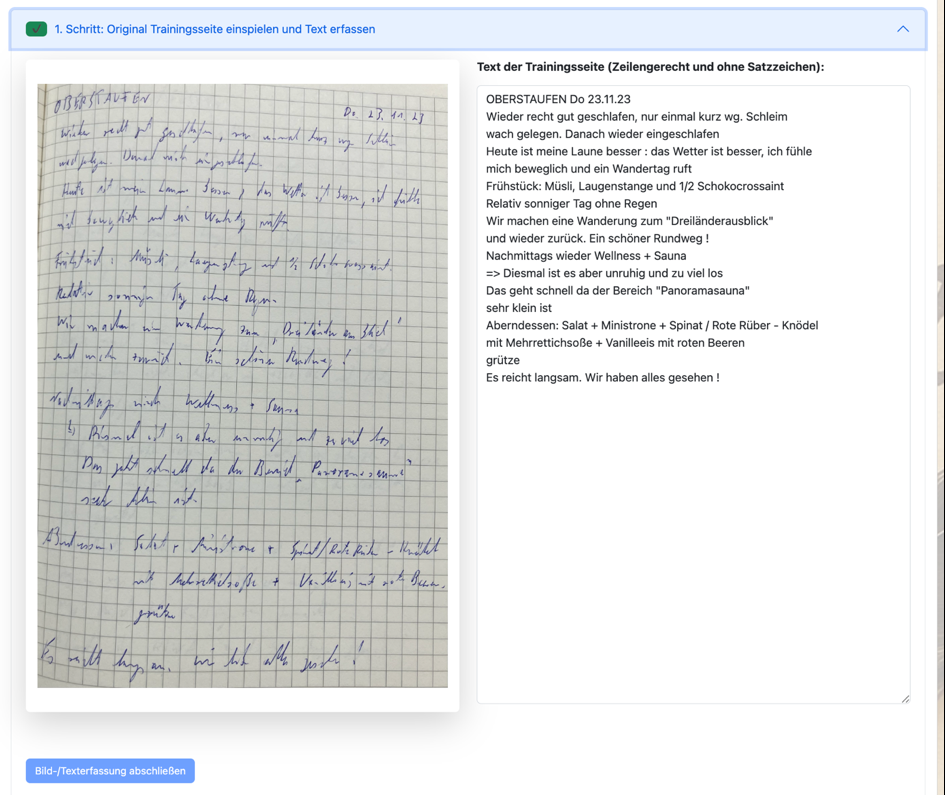
Raimund
26. August 2025 13:40
Im zweiten Schritt wird der Hintergrund über eine einmalig definierte Leerseite (also dem Hintergrund) herausgerechnet:
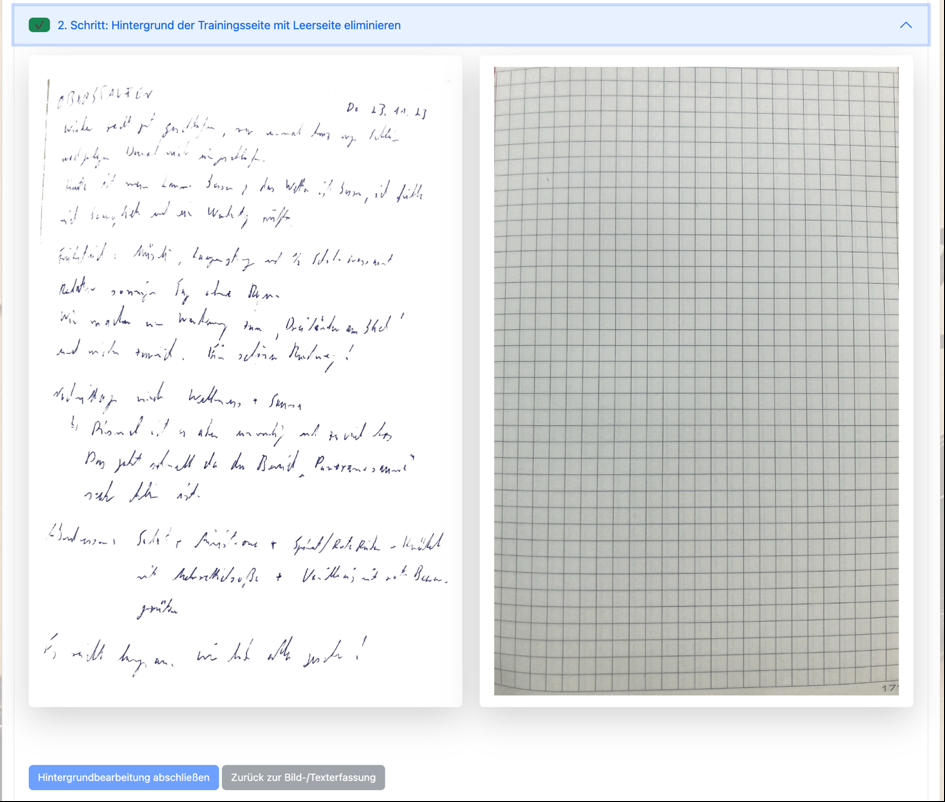
Raimund
26. August 2025 13:41
Im dritten Schritt wird der Text verstärkt und ggf. Unreinheiten, wie z.B. verbliebene Linien oder Kleckse, entfernt.

Raimund
26. August 2025 13:42
Im vierten Schritt wird der ermittelte Text nun in Textzeilen untergliedert. Dabei wird auf die ermittelten Parameter der individuellen Kalibrierung Deiner Schrift, die zum Modell oder User abgespeichert sind, zurückgegriffen.
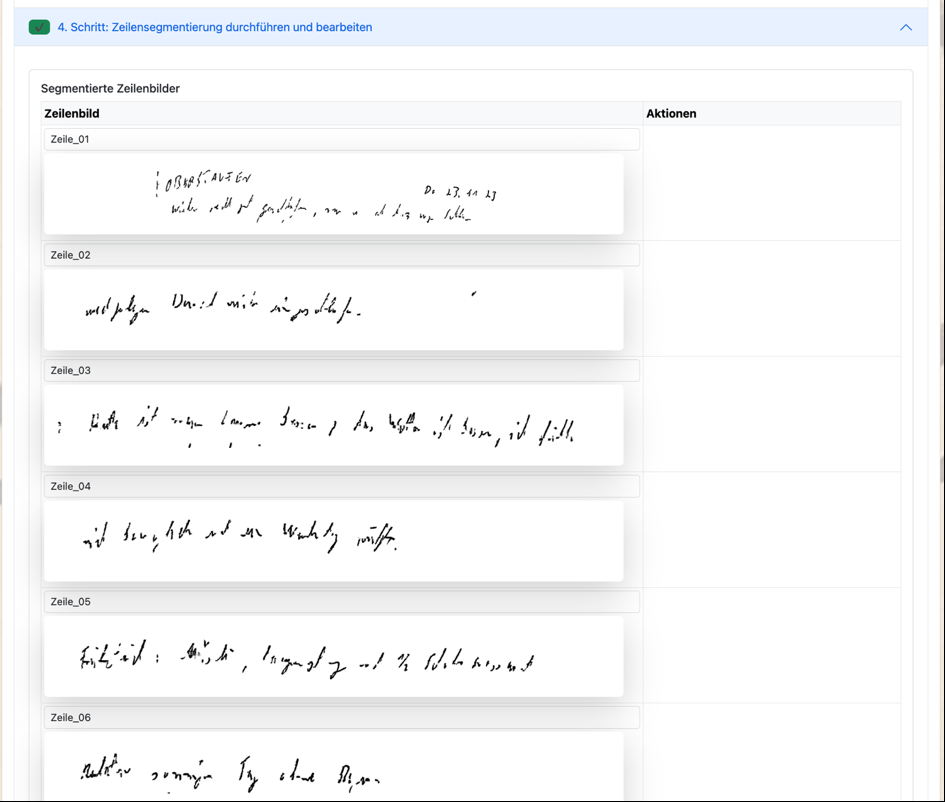
Raimund
26. August 2025 13:43
(Was meist gut funktioniert, aber manchmal (siehe Zeile 1) auch nicht ganz klappt)
Raimund
26. August 2025 13:43
Im fünften Schritt werden die Texte der Textzeilen automatisch in Wortbilder untergliedert. Auch hier wird auf die Parameter aus der Kalibrierung der Schrift zurückgegriffen. Zusätzlich werden zeilengerecht die einzelnen Worte aus der Texterfassung (Schritt 1) zugeordnet.
Dies kann natürlich nochmal überarbeitet werden. Zusätzlich kann den Wortbildern über ein Wortlevel noch ein Grad der Komplexität mitgegeben werden (Level 0 = Standardschrift; Level 1 = kompliziertes Wort; Level 2 und höher = außergewöhnliche Schreibweise).
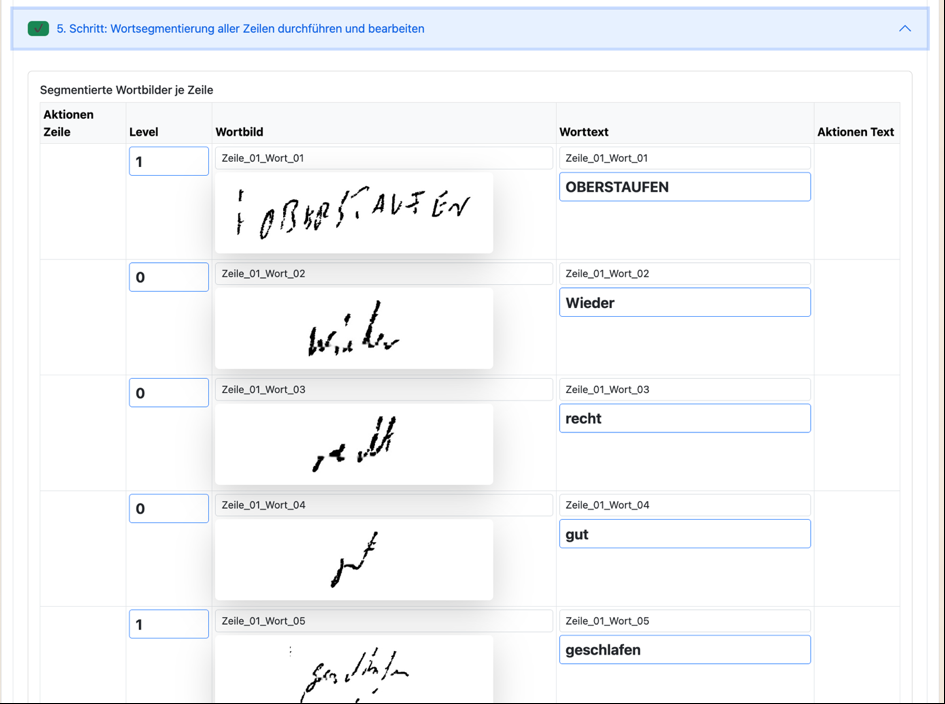
Raimund
26. August 2025 13:44
Wie habe ich mir nun das Training eines KI Sauklaue Modell vorzustellen?
Im Projekt KI Sauklaue erfolgt das Training als ein sogenanntes überwachtes Training auf der Basis von Trainings- und Textdaten.
Ein überwachtes Training basiert auf Trainings- und Testdaten, deren korrektes Ergebnis (als Label) bekannt sind. Beim Durchlauf der Trainingsdaten durch das Modell werden die Ergebnisse (als Vorhersagen) berechnet. Diese berechneten Ergebnisse werden mit den korrekten Ergebnissen verglichen (durch Anwendung einer Loss-Funktion). Durch Minimierungsfunktionen werden die Koeffizienten des neuronalen Netzes (unter Berücksichtigung einer Lernrate) angepasst, um dann einen neuen Trainingsdurchgang zu durchlaufen.
Die nachfolgende Übersicht versucht diesen Prozess zu visualisieren:
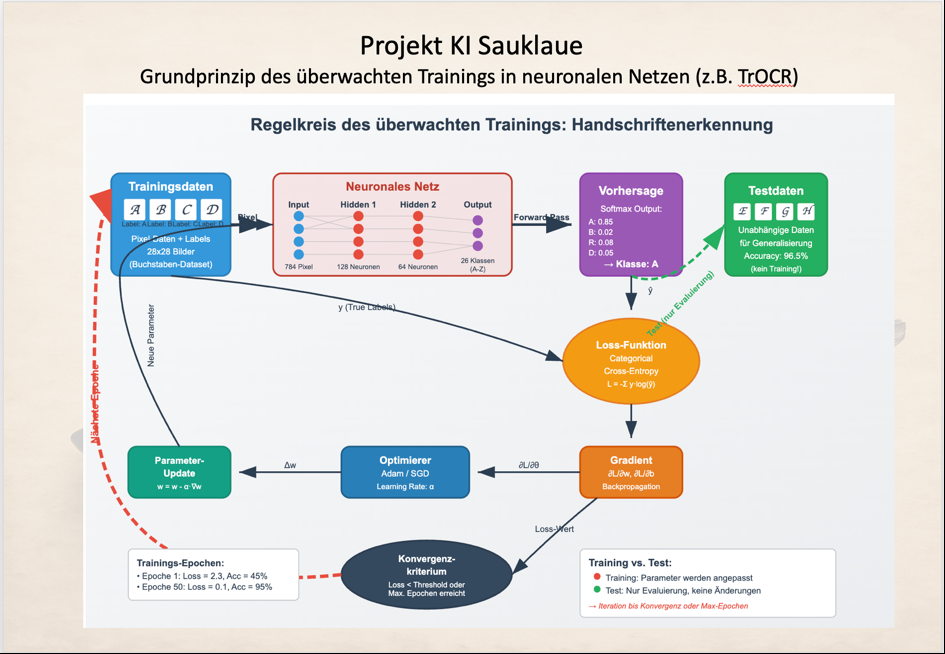
Raimund
26. August 2025 13:46
Die zuvor erzeugten Trainings-Wortbilder werden bei einem Trainingslauf dabei erneut in Trainingsdaten und Testdaten unterschieden. Das Durchlaufen der Trainingsdaten beeinflusst dabei die Koeffizienten des neuronalen Netzes. Das Netz versucht also aus den Trainingsdaten zu lernen.
Wenn alle Trainingsdaten einmal durchlaufen wurden, erfolgt ein weiterer Lauf mit Testdaten, die das Modell nicht mehr verändern. Hier wird nun untersucht, wie gut das Modell auf Basis der Trainingsdaten generalisieren kann und neue Testdaten korrekt erkennt. Auf diese Weise erhält man Angaben darüber, wie gut das Modell grundsätzlich die Trainingsdaten erlernen kann, aber eben auch, was noch wichtiger ist, wie gut es auf Basis dieses Lernens mit neuen Testdaten umgehen kann.
Das einmalige Durchspielen aller Trainingsdaten mit Anpassung der Koeffizienten im neuronalen Netz und anschließendem Testlauf mit den Testdaten nennt man eine Epoche. Für gewöhnlich braucht 50-60 Epochen um bei dem Training immer bessere und sichere Ergebnisse zu erzielen. Ein komplettes Training dauert daher je nach Hardware und Umfang der Trainingsdaten zwischen 15 – 60 Stunden.
Raimund
26. August 2025 13:47
Was muss ich noch wissen, um das Training eines KI Sauklaue Modell zu verstehen?
Das Training selbst wird mit verschiedenen Parametern über den gesamten Zeitraum hinweg kontrolliert und gesteuert. Hier sind zunächst die wichtigsten Begriffe beim überwachten Training eines TrOCR-Systems einfach erklärt:
Epoche
Ein vollständiger Durchgang durch den gesamten Trainingsdatensatz. Während einer Epoche wird jedes Trainingsbeispiel einmal dem Modell gezeigt. TrOCR wird typischerweise über mehrere Epochen trainiert, wobei das Modell mit jeder Epoche seine Parameter verfeinert.
Steps und Batch-Größe
Die Anzahl der Parameteraktualisierungen (Gewichtsupdates) während des Trainings. Ein Step entspricht der Verarbeitung eines Mini-Batches. Bei 1000 Trainingsbeispielen und einer Batch-Größe von 8 ergeben sich 125 Steps pro Epoche.
Train-Loss
Der Verlustfunktionswert auf den Trainingsdaten, der misst, wie stark die Vorhersagen des Modells von den tatsächlichen Zielwerten abweichen. Bei TrOCR ist dies typischerweise die Cross-Entropy-Loss zwischen vorhergesagten und echten Textsequenzen. Ein sinkender Train-Loss zeigt, dass das Modell lernt.
Grad_Norm
Die Norm (meist L2-Norm) des Gradientenvektors, die angibt, wie stark sich die Modellparameter in einem Trainingsschritt ändern sollen. Sehr hohe Werte deuten auf das "Exploding Gradient"-Problem hin, sehr niedrige auf "Vanishing Gradients". Typische Werte liegen zwischen 0.1 und 10.
Eval-Loss
Der Verlustfunktionswert auf den Validierungs- bzw. Testdaten, der die Generalisierungsfähigkeit des Modells misst. Steigt die Eval-Loss während die Train-Loss sinkt, deutet dies auf Overfitting hin. Bei TrOCR sollte die Eval-Loss idealerweise parallel zur Train-Loss sinken.
CER (Character Error Rate)
Die Zeichenfehlerrate, die den Prozentsatz falsch erkannter Zeichen misst. Berechnet als: (Substitutionen + Einfügungen + Löschungen) / Gesamtzahl der Zeichen × 100. Ein CER von 5% bedeutet, dass 95% der Zeichen korrekt erkannt wurden.
WER (Word Error Rate)
Die Wortfehlerrate, analog zur CER aber auf Wortebene. Besonders relevant bei OCR, da ein einzelner Zeichenfehler ein ganzes Wort falsch machen kann. WER ist meist höher als CER, da bereits ein falsches Zeichen das ganze Wort als falsch wertet.
Lernrate (Learning Rate)
Bestimmt die Schrittgröße bei der Parameteraktualisierung. Zu hohe Lernraten führen zu instabilem Training, zu niedrige zu langsamem Lernen. Bei TrOCR werden oft adaptive Lernraten-Scheduler verwendet, die die Rate während des Trainings anpassen (z.B. 1e-5 bis 1e-7).
Data Augmentation
Techniken zur künstlichen Vergrößerung des Trainingsdatensatzes durch Transformationen der Eingabebilder. Bei TrOCR typisch: Rotation, Skalierung, Rauschen hinzufügen, Helligkeits-/Kontraständerungen, perspektivische Verzerrungen. Verbessert die Robustheit gegenüber verschiedenen Bildqualitäten.
Zu den wichtigsten Verfahren mit den Parametern beim Data Augmentation zählen dabei:
Geometrische Transformationen
RandomRotation
• Rotiert Bilder zufällig um einen Winkel aus dem Bereich (± Grad der Drehung)
• fill=(255,) füllt entstehende leere Bereiche mit weißen Pixeln
• Simuliert leicht schräg gescannte oder fotografierte Dokumente
RandomAffine
Kombiniert mehrere geometrische Transformationen:
• translate: Verschiebt das Bild um einen Prozentsatz der Bildgröße (z.B. ±5%)
• scale: Skaliert das Bild (z.B. zwischen 95% und 105% der Originalgröße)
• shear: Verzerrt das Bild durch Scherung
• fill: Füllt leere Bereiche mit dem angegebenen Wert
Farbmanipulation
ColorJitter
• brightness: Variiert die Helligkeit des Bildes
• contrast: Verändert den Kontrast
• Besonders relevant für reale Scan-Bedingungen mit unterschiedlichen Belichtungen
Bildqualitätssimulation
GaussianBlur
• kernel_size: Größe des Blur-Kernels (ungerade Zahl)
• sigma: Standardabweichung des Gauß-Filters (Bereich zwischen sigma1 und sigma2)
• Simuliert leicht unscharfe Scans oder Kameraaufnahmen
Drop-Outs
Regularisierungstechnik, bei der zufällig ausgewählte Neuronen während des Trainings "ausgeschaltet" werden. Verhindert Overfitting, indem das Modell nicht zu stark von einzelnen Neuronen abhängig wird. Typische Dropout-Raten liegen bei 0.1-0.3 (10-30% der Neuronen werden deaktiviert).
Weight Decay
L2-Regularisierung, die große Gewichtswerte bestraft, indem ein Strafterm zur Loss-Funktion hinzugefügt wird. Verhindert Overfitting und fördert einfachere Modelle. Der Weight Decay-Parameter (z.B. 0.01) kontrolliert die Stärke dieser Regularisierung. Zu hohe Werte können das Lernen behindern.
Raimund
26. August 2025 13:51
Wie sehen nun konkret die Trainingsergebnisse im KI Sauklaue Model bei einer individuellen unleserlichen Handschrift aus?
In den nachfolgenden Grafiken sind mehrere Trainingsläufe mit unterschiedlichen Parametern durchgespielt worden. Dabei zeigt sich grundsätzlich bei allen Parametrisierungen folgendes Bild:
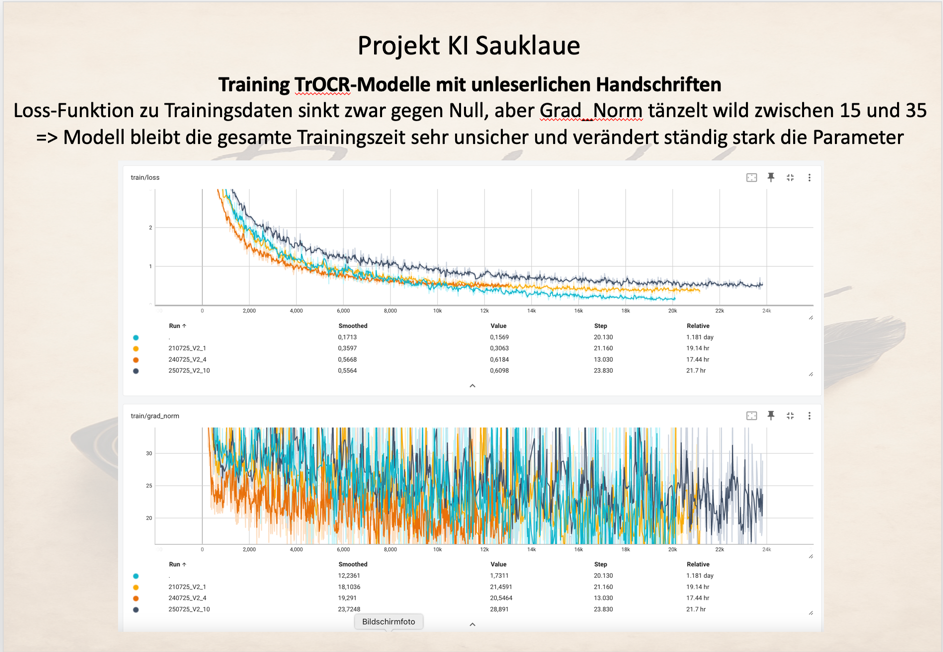
Raimund
26. August 2025 13:53
Die Train-Loss Funktion sinkt zwar mit Fortschreiten des Trainings gegen Null, aber die Grad_Norm Funktion tänzelt über den gesamten Trainingszeitraum über sehr hohe Werte von 15 bis 35 hin und her. Das bedeutet, dass die Trainingsdaten zwar recht gut gelernt werden, aber das System in Summe extrem unsicher bleibt und bei jedem Durchlauf starke Veränderungen stattfinden.
Das Modell findet keine sicheren Koeffizienten für das neuronale Netz.
Hier kommen die Grenzen des reinen TrOCR-Modells zum Tragen, die Worte nicht eindeutig erkennen können, deren Wortendungen z.B. undeutlich geschrieben sind, und daher mal „hab“, „habe“ oder „haben“ bedeuten, obwohl die ähnlich aussehen. Auch fehlende oder verkürzte Schreibweisen, die nur durch den Themenkontext ersichtlich sind, kann ein TrOCR nicht erkennen und bleibt dadurch weitgehend verwirrt.
Das hat natürlich auch Einfluss auf die Eval-Loss-Funktion und die Character Error Rate (CER):
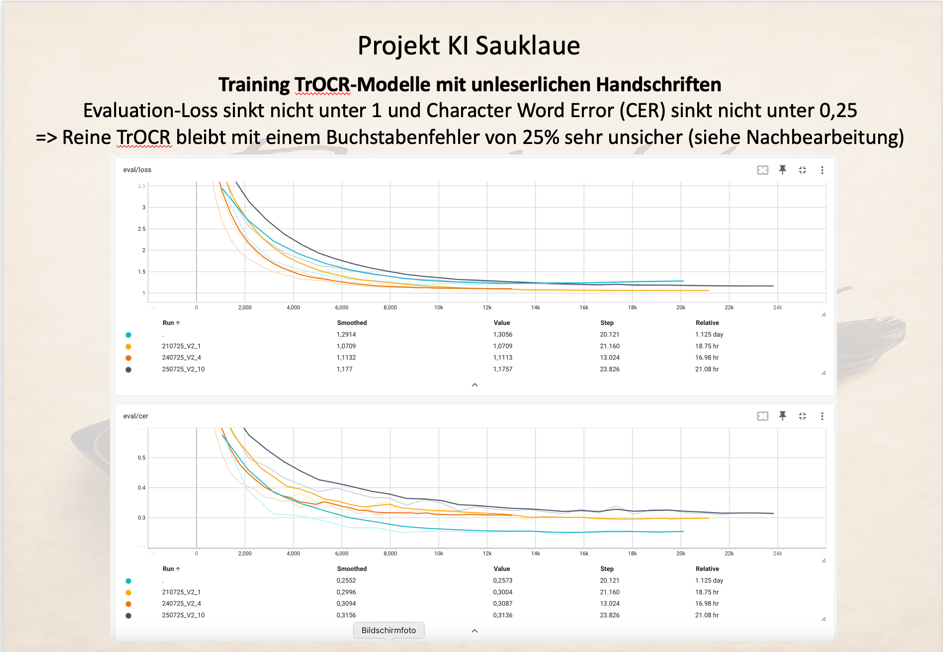
Raimund
26. August 2025 13:55
Aber trotzdem kann man auch erkennen, dass auch bei einer unleserlichen Handschrift mit einem CER von 0,25 etwa erreicht werden kann, dass 75% der Buchstaben korrekt erkannt werden können.
Raimund
26. August 2025 13:55
Lernrate
Generell hat sich beim Training auch gezeigt, dass das Modell in Bezug auf seine vortrainierten Werte sehr empfindlich ist. Um ein aufbauendes und verbessernden Training mit der individuellen Handschrift zu erreichen, durfte die Lernrate nicht größer als 1e-6 sein und musste während des Trainings sukzessive abnehmen:
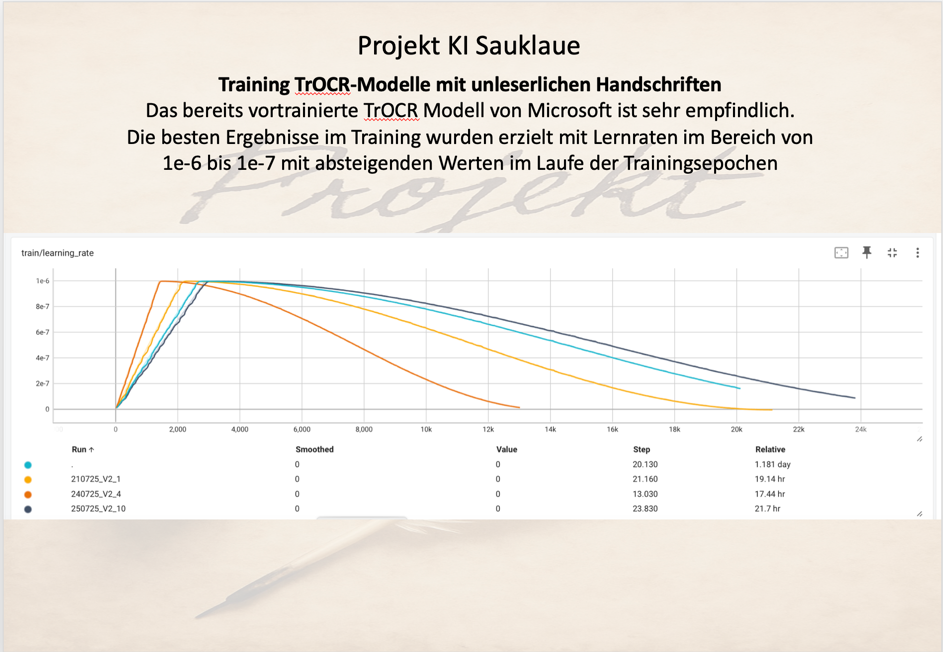
Raimund
26. August 2025 13:57
Bei größeren Lernraten wurden schlechtere Ergebnisse erzielt, da damit das grundlegende Training zur Handschriftenerkennung „überschrieben“ wurde.
Raimund
26. August 2025 13:57
Curriculum-Learning
Curriculum Learning ist eine weitere Trainingsmethode, bei der das Modell mit Beispielen zunehmender Schwierigkeit trainiert wird, beginnend mit einfachen und fortschreitend zu schwierigeren Trainingsbeispielen. Diese Strategie orientiert sich an der Art, wie Menschen lernen.
Grundprinzip
Das Modell wird auf Beispielen mit steigender Schwierigkeit trainiert, wobei die Definition von "Schwierigkeit" extern vorgegeben oder als Teil des Trainingsprozesses entdeckt werden kann Curriculum learning.
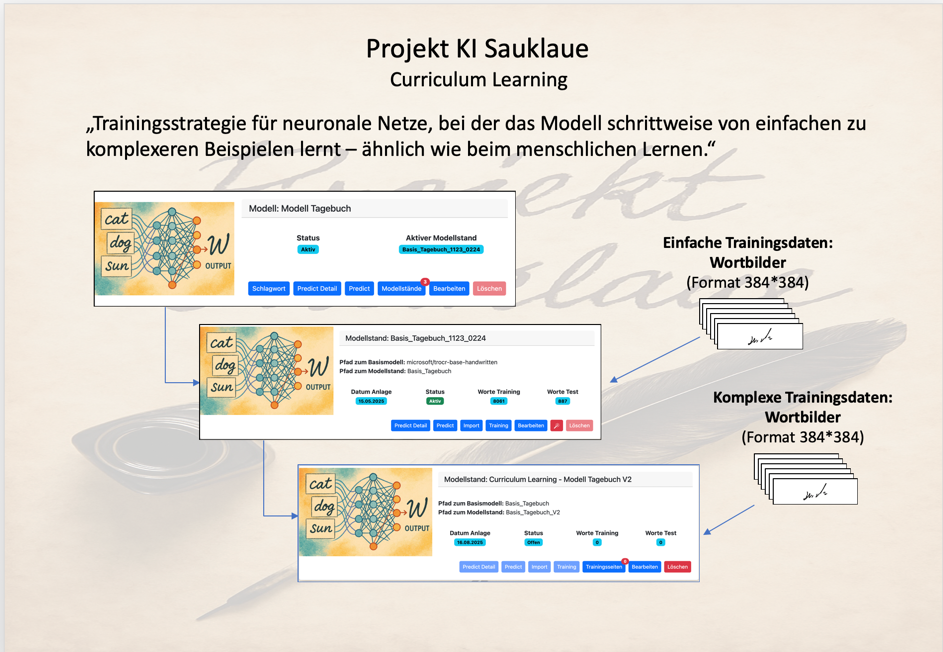
Umsetzung im Projekt KI Sauklaue mit „Wortleveln“
Im Falle des Projektes KI Sauklaue werden dabei ein neuer Modellstand eines Modells auf dem Ergebnis eines anderen Modellstandes des gleichen Modells trainiert:
Raimund
26. August 2025 13:58
Dabei werden dem ersten Modellstand nur Wortbilder aus den Trainingsdaten übergeben, die eine einfache Lesbarkeit oder Verständlichkeit beinhalten. In diesem Modellstand wird das Basismodell von Microsoft, wie z.B. trocr-base-handwritten, mit diesen Daten zu einem neuen Modell trainiert.
Dem zweiten Modellstand, der das Ergebnis des ersten Modellstandes als Ausgangsbasis für sein Training nimmt, erhalt nun diese einfache und zusätzlich komplexe Wortbilder für sein Training zur Verfügung gestellt. Das anschließende Training verfeinert das Ergebnis des ersten Modellstandes noch einmal und erzeugt wieder ein neues Modell.
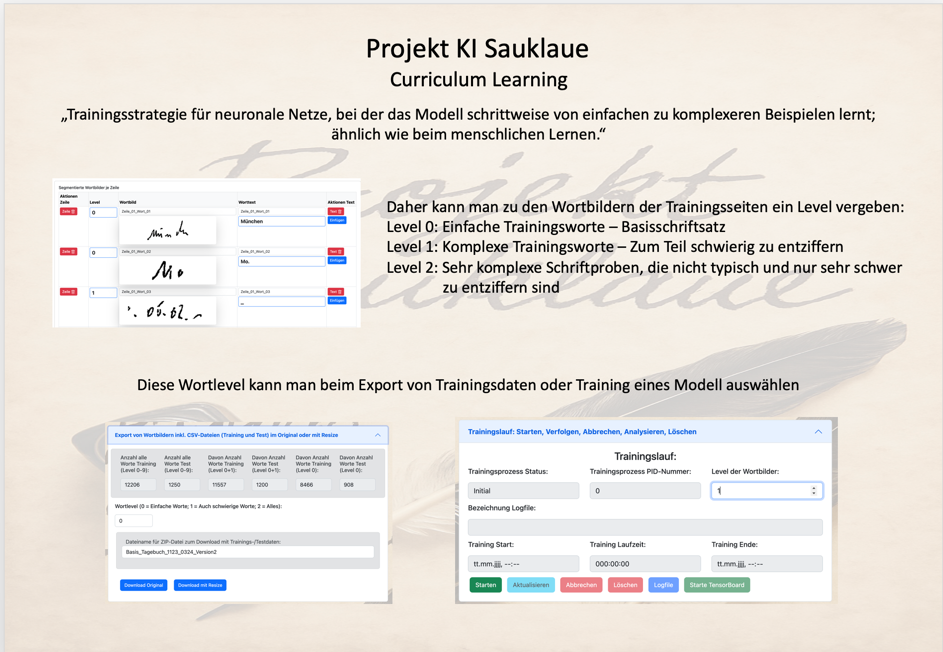
Um dieses Trainingsverfahren zu unterstützen, ist es bei der Aufbereitung der Trainingsdaten möglich, den einzelnen Wortbildern ein „Wortlevel“ mitzugeben:
Raimund
26. August 2025 14:00
Das Wortlevel bestimmt, ob ein Wortbild zum Basisschriftsatz (Level 0) gehört, zu schwierig zu entziffernden Worten (Level 1) zu zählen ist oder ein untypisches und nur sehr schwer zu erkennendes Wort (Level 2 und höher) handelt.
Beim Training oder Exportieren von Trainingsdaten kann dann definiert werden, welches Wortlevel 0, 1 oder höher zu benutzen ist.
Wichtig ist dabei, dass mit fortschreitenden Stufen des Trainings die Lernrate deutlich nach unten zu korrigieren ist. Andernfalls wird das Ergebnis der vorhergehenden Stufen wieder verwischt:

Raimund
26. August 2025 14:01
Dies beschränkt bei einem TrOCR den Curriculum Learning Prozess auf maximal 2 bis 3 Stufen, da bereits bei der ersten Stufe relativ niedrige Lernraten anzuwenden sind.
Raimund
26. August 2025 14:01
Over- und Underfitting
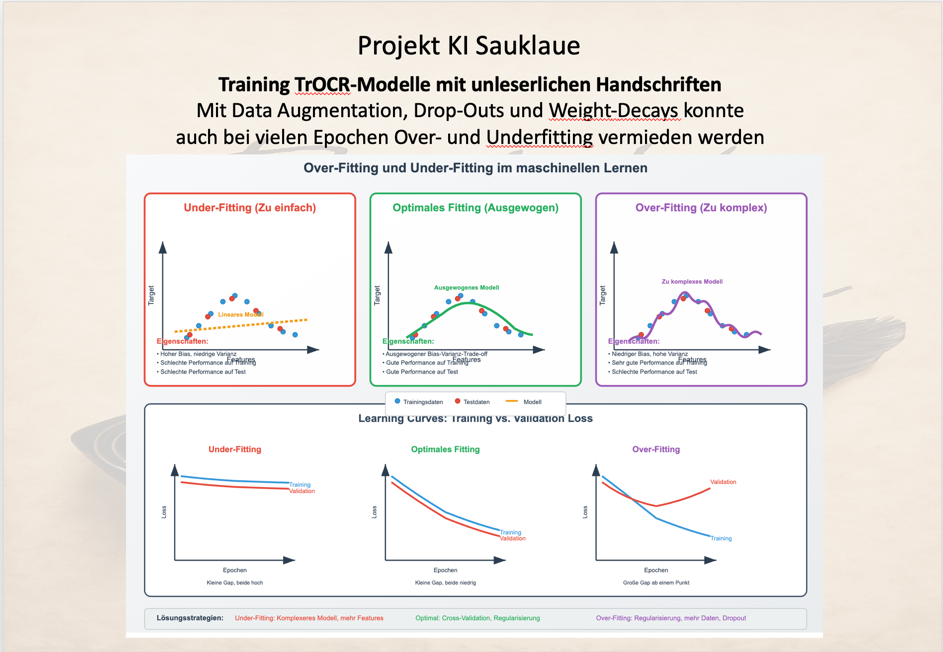
Ein typisches Problem beim Training von TrOCR-Systemen liegt im feinen Austarieren zwischen Over- und Underfitting.
Unter Overfitting wird der Prozess verstanden, dass das TrOCR-Modell die Trainingsdaten sehr genau lernt, aber damit seine generalisierende Funktion verliert. Mit anderen Worten: Das Modell will mit allen Mitteln exakt die Trainingsdaten wieder erreichen und erzeugt dabei ggf. auch extreme und absurde Koeffizienten.
Unter Underfitting wird der Prozess verstanden, dass das TrOCR-Modell um möglichst eine hohe Allgemeingültigkeit zu erhalten, auf die spezifischen Eigenschaften der Trainingsdaten zu wenig eingeht und damit eine zu starke Vereinfachung in seinem Modell abbildet.
Die nachfolgende Grafik versucht diese Problematik zu verdeutlichen:
Raimund
26. August 2025 14:04
Bei einem optimalen Fitting wird aus den Daten des Trainingsmaterial eine echte neue Struktur für das Modell gelernt, ohne aber zu speziell zu werden und damit eine Generalisierung auf neue Validierungs- bzw. Testdaten zu verlieren.
Raimund
26. August 2025 14:05
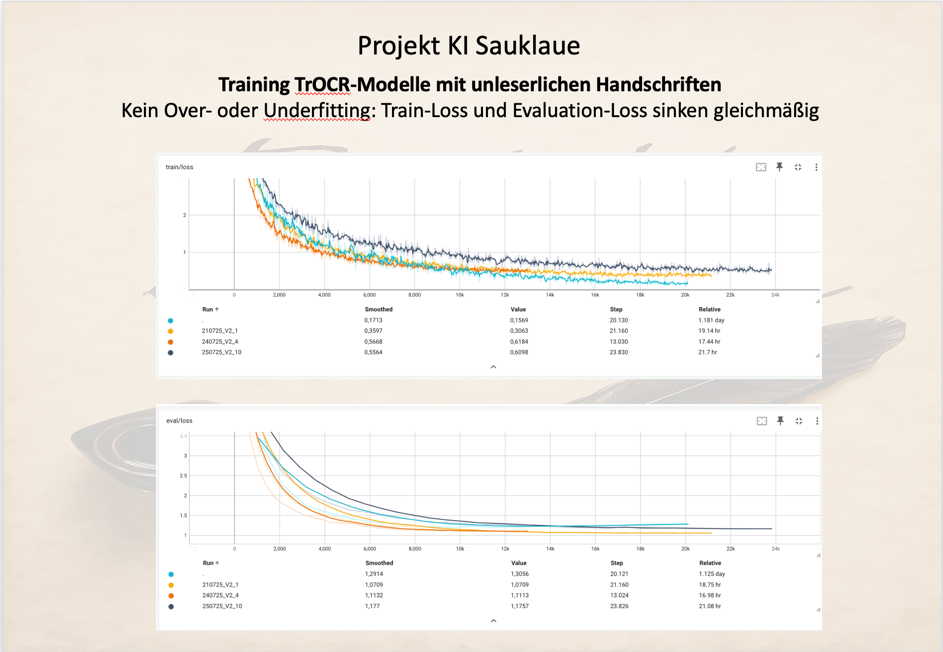
Ein gutes Fitting erkennt man grundsätzlich daran, dass die Train-Loss-Funktion und die Eval-Loss-Funktion in ähnlicher Weise während des Trainingslaufes verlaufen.
Dies wurde im Projekt KI Sauklaue durch die Anwendung von einem leichten Data Augmentation, d.h. dem leichten verzerren der Trainingsdaten nach jedem kompletten Durchlauf, erreicht. Zusätzlich wurden mit Drop Outs von 0,3 und Weight Decays von 0,01 verhindert, dass sich Trainingsergebnisse auch bei vielen Trainingsepochen zu sehr festsetzen.
Raimund
26. August 2025 14:05
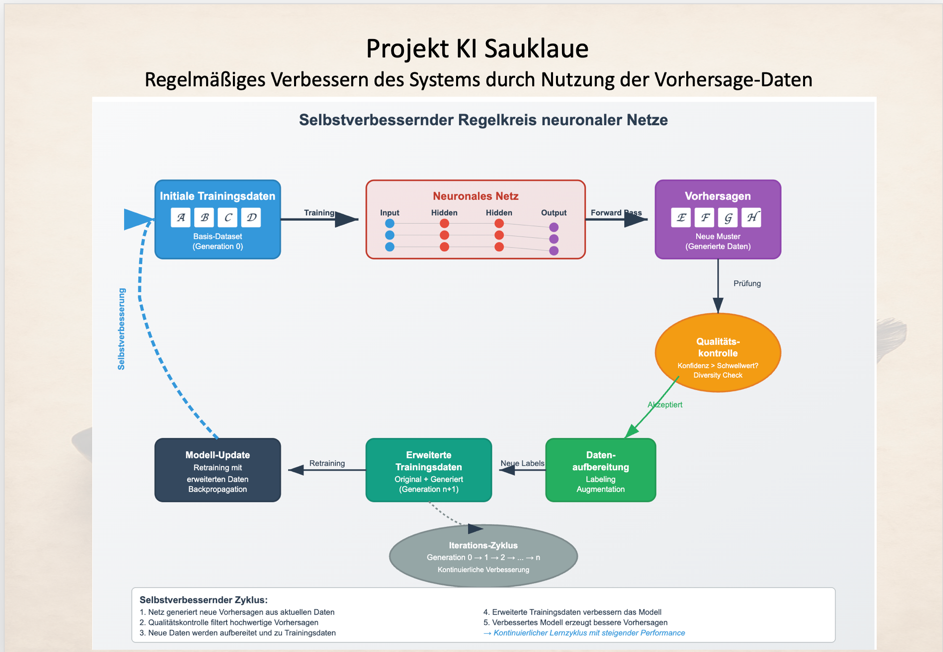
Verbesserung des Modells: Vorhersagen zu Trainingsdaten
Ein trainiertes TrOCR-Modell kann durch die Nutzung der Vorhersage-Daten regelmäßig verbessert werden:
Raimund
26. August 2025 14:07
Dazu werden wie besten Vorhersagen als neue Trainingsdaten übernommen. Sofern die Ergebnisse nicht perfekt sind, werden hier zunächst die Ergebnisse im Rahmen der Datenaufbereitung korrigiert und wieder neue Wortbilder für ein neues Training erzeugt.
Auf diese Weise kann das Trainingsmaterial für das Modell erweitert und in Summe verbessert werden. Durch diesen kontinuierlichen Lernzyklus wird das System durch einen immer größeren Wortschatz und Varianten in der Schreibweise in Deiner Handschrift auf eine sichere Basis gestellt.
Bei dieser Form des zyklischen Trainings wird aber nicht das Curriculum Learning angewendet, sondern ein komplett neuer Modellstand mit den insgesamt erweiterten Trainingsdaten neu trainiert.
Raimund
26. August 2025 14:07
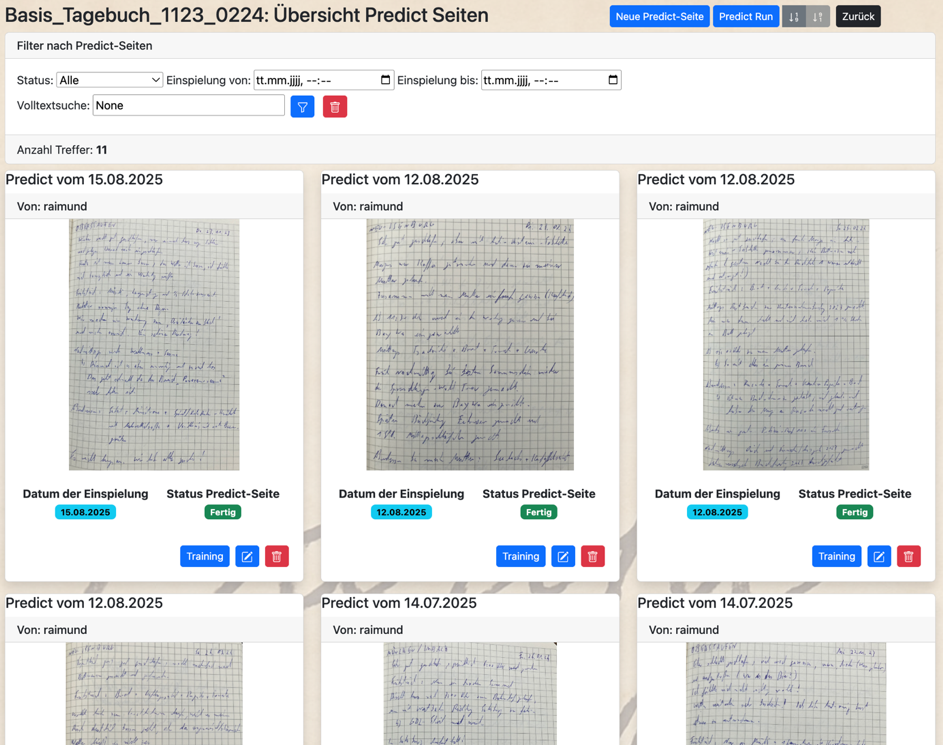
Im Projekt KI Sauklaue kann das Ergebnis einer abgeschlossenen Predict-Seite (Vorhersage) einfach über einen Button „Training“ als eine neue Trainingsseite übernommen werden:
Raimund
26. August 2025 14:08
Zusammenfassung:
Zusammenfassend lässt sich sagen, dass man mit den komfortabel zu erstellenden Trainings-Wortbildern und den verschiedenen Techniken und Methoden ein KI Sauklaue Modell relativ gut auf Deine Handschrift trainieren kann.
Aber das TrOCR-System wird alleine aus der Analyse der Handschrift einzelner Wortbilder nie perfekt werden, weil es semantische Zusammenhänge in einem Satzgebilde oder verkürzte Schreibweisen zu Worten, die in einem Themenkontext stehen, nicht erkennen kann. Ein derartiges TrOCR-System wird alleine immer sehr unsicher und unstabil bleiben.
Aus diesem Grund braucht es einen Nachbearbeitungs-Schritt mit einem Large-Language-Modell, dass genau diese semantischen und themenspezifischen Zusammenhänge erkennen kann und den Text entsprechend korrigieren bzw. erweitern kann.
Raimund
26. August 2025 19:34
Link zu KI Sauklaue - Einführung