KI Sauklaue - Strukturelemente
Raimund
26. August 2025 15:20
Strukturelemente und Vorgehen zum Einrichten eines eigenen Modells
Was kann das Projekt „KI Sauklaue“ und wie ist es aufgebaut?
Das Projekt KI Sauklaue ist grundsätzlich so gestaltet, dass jeder User nach einer Registrierung seine eigenen individuellen Modelle zur Erkennung seiner eigenen Handschrift erstellen kann.
Die Individualität der eigenen Handschrift bedingt, dass es kein Default-Modell und keine Vorlagen für die Trainingsdaten gibt. Diese müssen jeweils neu erarbeitet werden.
Das Projekt KI Sauklaue bietet aber einen vollständigen Rahmen, um
-
Trainingsdaten auf Basis von Fotos zu erfassen
-
Hintergrund-Informationen zu den Texten in Form von Leerseiten zu definieren, um sie später für die Texterkennung herausrechnen zu lassen
-
Die eigene Handschrift auf Basis von Modellparametern zu kalibrieren
-
Ein TrOCR-Modell mit seinen eigenen Trainingsdaten trainieren zu lassen oder
-
Trainingsdaten zu exportieren, lokal das TrOCT-Modell trainieren zu lassen und das trainierte Modell wieder zu importieren
-
Ein nachgelagertes Large Language Modell (LLM, z.B. ChatGPT) zu konfigurieren, z.B. auch in der Pflege einer Schlagwortliste für bestimmte Themenkontexte
-
Vorhersagen (Predict) zu neuen handschriftlichen Texten entweder online oder über eine API berechnen zu lassen
Zum Verständnis des Projektes „KI Sauklaue“ werden nun die wesentlichen unabhängigen Strukturelemente vorgestellt:
Raimund
26. August 2025 15:22
Der User und sein Profil:
Jeder Anwender muss sich einmalig registrieren. Damit wird ein eigener User eingerichtet, mit der Anwender in das Projekt KI Sauklaue einsteigen kann.
Kein User kann auf die Daten oder Modelle anderer User zugreifen. Dies wird über permanente User-Berechtigungen abgeprüft.
Zu jedem User wird bei der Anlage ein Profil mit Standardwerten für
-die Erstellung der Trainingsdaten und die Kalibrierung der Handschrift
-
das Training der TrOCR-Modelle
-
die Vorhersagen mit einem trainierten Modellstand
-
die Konfiguration des LLM-Modells zur Nachbearbeitung
eingerichtet.
Jeder User kann seine eigenen Profildaten überarbeiten.
Beim Anlegen neuer Strukturelemente, wie Modellstände, Trainingsseiten, Leerseiten wird immer auf die Standardwerte aus dem Profil des Users zurückgegriffen.
Raimund
26. August 2025 15:23
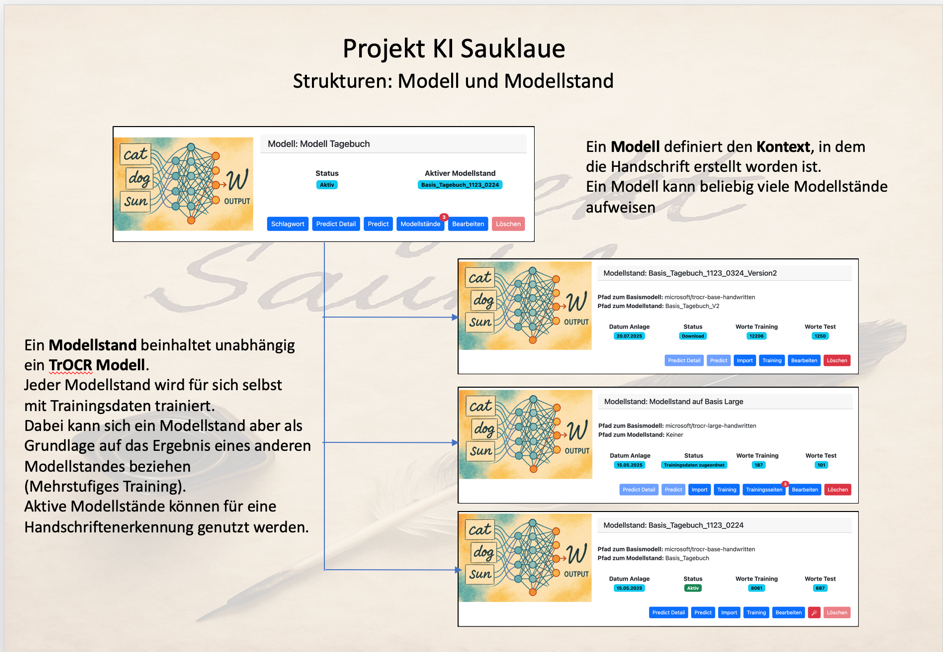
Das Modell mit seinen Modellständen:
Raimund
26. August 2025 15:24
Jeder User kann beliebig viele Modelle definieren. Ein Modell definiert den Kontext, in dem die Handschrift erstellt worden ist.
Um diesen Kontext zu beschreiben, kann zu jedem Modell eine Schlagwortliste gepflegt werden, die die typischsten oder spezifischsten Begriffe in diesem Kontext beinhaltet.
Jedes Modell kann beliebig viele Modellstände besitzen, benötigt aber, um aktiv zu werden, mindestens einen aktiven Modellstand.
Ein Modellstand beinhaltet unabhängig von den anderen Modellen und Modellständen ein eigenes TrOCR-Modell.
Jeder Modellstand wird für sich selbst mit Trainingsdaten auf der Grundlage eines Basismodells (z.B. Microsoft TrOCR-base-handwritten) trainiert.
Bei einem mehrstufigen Training (Curriculum Learning) kann auch das TrOCR Modell eines aktiven Modellstandes als Grundlage für ein weiteren Modellstand eingesetzt werden.
Jeder Modellstand besitzt einen Status (Offen, Trainingsdaten zugewiesen, Training abgeschlossen, exportiert, importiert, aktiv). Nur zu aktiven Modellständen kann eine Vorhersage vorgenommen werden.
Besitzt ein Modell ein aktiven Modellstand ist auch das gesamte Modell aktiv. Besitzt ein Modell mehrere aktive Modellstände, so wird für das Modell immer der neueste aktive Modellstand genutzt.
Raimund
26. August 2025 15:27
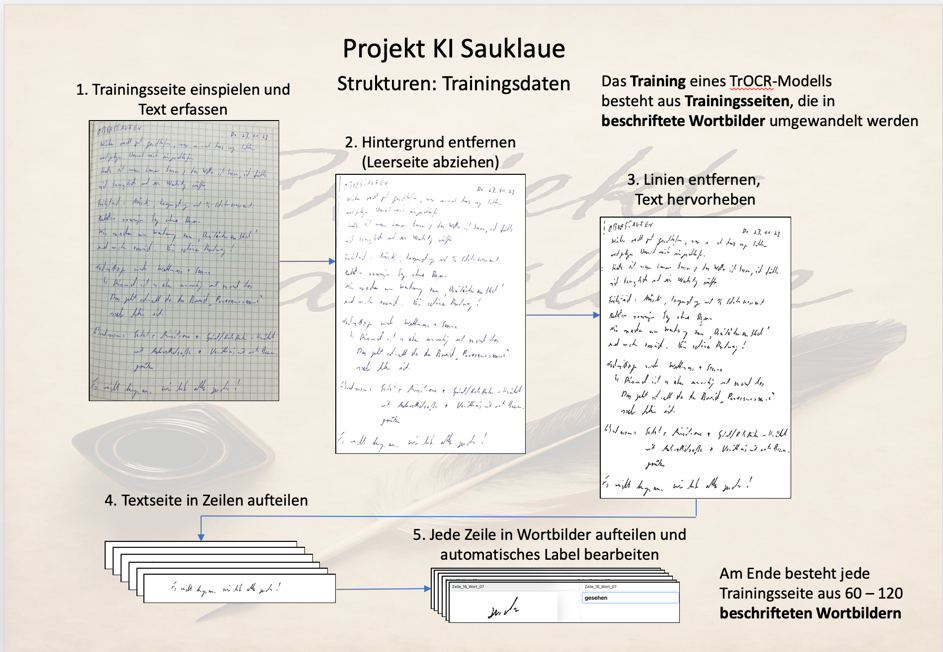
Die Trainingsseiten mit ihren Trainingsdaten:
Raimund
26. August 2025 15:27
Wichtig für den Umgang im Projekt „KI Sauklaue“ ist das Verständnis, dass die Trainingsseiten mit ihren Trainingsdaten (beschriftete Wortbilder) unabhängig von den Modellen oder Modellständen eingerichtet werden.
In einem weiteren Schritt werden dann zu einem Modellstand Trainingsseiten mit ihren Daten zugeordnet. Damit ist es möglich, einmal erstellte Trainingsseiten mehrfach für verschiedene Modelle und Modellstände einzusetzen.
Eine Trainingsseite besteht dabei aus einem Foto der eigenen Handschrift mit einer zeilengerechten Beschreibung des Inhaltes der Textseite.
Über mehrere Bearbeitungsschritte (Hintergrund entfernen, Textextrahierung, Zeilensegmentierung, Wortsegmentierung) werden aus einer Trainingsseite viele (bei einer DIN A5-Seite ca. 60 – 120) beschriftete Wortbilder, die dann für das Training von Modellständen genutzt werden können.
Dabei kommen zahlreiche Parameter in der Bearbeitung der eigenen Handschrift zum Tragen. Aus der Anpassung dieser Parameter entsteht eine individuelle Kalibrierung der Handschrift für die Texterkennung. Diese wird später sowohl für das Training, als auch für Vorhersagen neuer Texte herangezogen. Es empfiehlt sich diese Parameter im eigenen User-Profil zu hinterlegen, um sie jede Trainingsseite automatisch anwenden zu können.
Raimund
26. August 2025 15:29
Die Leerseiten (Hintergrundentfernung):

Raimund
26. August 2025 15:30
Die Erfassung von Trainingsseiten soll möglichst praxisnah und einfach erfolgen. Ziel ist es dabei, normale handschriftliche Texte, so wie sie im Alltag erstellt werden, auch in KI Sauklaue zu erfassen und bearbeiten zu lassen.
Dazu gehört auch, dass der handschriftliche Text nicht auf einem reinen weißen Papier, sondern in einem Heft, einem Buch oder einer anderen Unterlage (mit entsprechenden Strukturen (Linien, Karos) oder Farben (mit und ohne Abbildungen/Mustern)) erstellt werden kann. Wenn derartige Texte fotografiert und für ein Training oder für eine Vorhersage erkannt und genutzt werden sollen, ist es notwendig, den handschriftlichen Text zunächst einmal von dem Hintergrund zu trennen und den Hintergrund heraus zurechnen.
Ein sehr bewährtes, sehr flexibles und relativ einfaches Verfahren besteht dabei darin, von dem Untergrund/Hintergrund des handschriftlichen Textes ein eigenes Foto, von uns „Leerseite“ genannt, zu erstellen.
Zu diesem Foto werden dann die wesentlichsten Farben (z.B. 50 – 100 Farben) mit ihren Farbkorridoren berechnen zu lassen.
Beim Herausrechnen des Hintergrundes werden dann vom Original-Foto genau diese Farben herausgerechnet. Ist die Anzahl der Farben mit ihrem Farbkorridor umfangreich genug, aber nicht zu allgemein, um auch die Stiftfarbe zu eliminieren, kann auf diese Weise der Hintergrund zuverlässig entfernt werden.
Auch diese Leerseiten werden einmalig unabhängig von den Trainingsseiten definiert. Damit kann eine Leerseiten beliebig häufig von einer Trainingsseite genutzt/zugeordnet werden, um den Hintergrund der Trainingsseite zu entfernen.
Raimund
26. August 2025 15:32
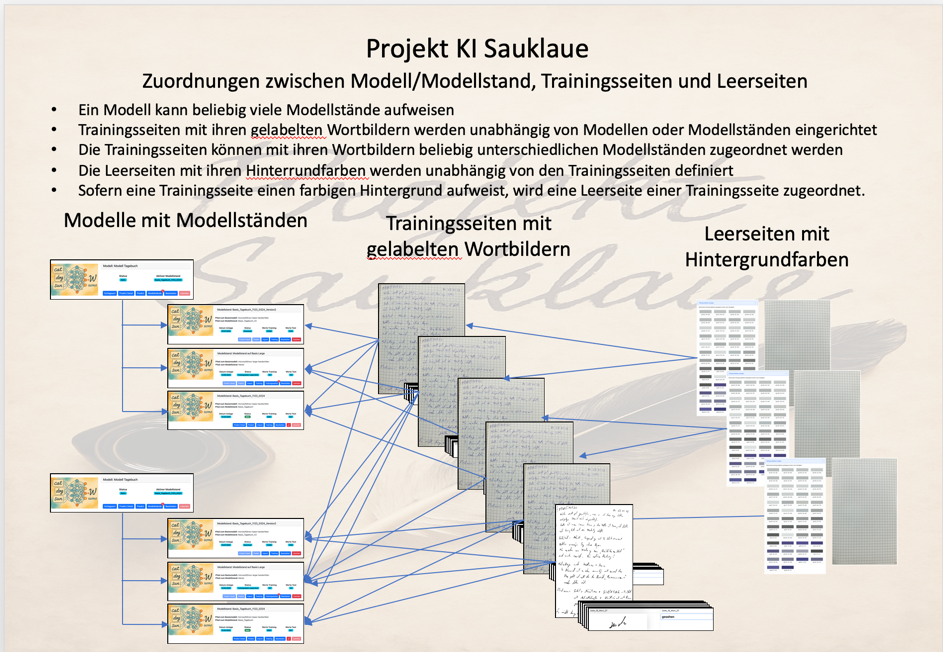
Zuordnungen zwischen Modell/Modellstand, Trainingsseiten und Leerseiten
Die nachfolgende Grafik erläutert zusammenfassend wie die einzelnen unabhängigen Strukturelemente Modell/Modellstand, Trainingsseiten und Leerseiten untereinander zugeordnet werden:
Raimund
26. August 2025 15:33
Wie gehe ich nun konkret vor, um mein eigenes Modell für meine Handschrift zu erstellen?
Das die Strukturelemente Modell/Modellstände und Trainingsseiten unabhängig voneinander definiert werden, gibt es auch keine feste Reihenfolge, welche Strukturen man zuerst definieren sollte.
Es hat sich aber gezeigt, dass es Sinn macht, vor der Definition des Modells und eines Modellstandes zunächst einmal mit den Trainingsseiten zu beginnen.
Raimund
26. August 2025 15:33
Warum ist es sinnvoll zunächst mit den Trainingsseiten zu beginnen?
Es ist mit Abstand die umfangreichste Arbeit für den Anwender, den ihm auch niemand abnehmen kann. Nur er hat die Fotos zu seiner Handschrift und nur er hat die zuverlässige Information, welche Inhalte seine unleserliche Handschrift beinhaltet.
Ohne Abschrecken zu wollen, muss man sich im Klaren sein, dass für ein Erfolg versprechendes Training eines TrOCR Modells ca. 8.000 – 15.000 beschriftete Wortbilder notwendig sind. Dies entspricht in etwa dem Text von 150 DIN A5-Seiten (je nach Handschrift). Wenn man während der Erstellung der Trainingsseiten merkt, dass man diese Trainingsdaten nicht besitzt oder nicht erfassen möchte, sind die weiteren Schritte wenig erfolgversprechend.
Weiterhin erlernt man in der Erstellung von Trainingsseiten und darauf folgend in der Bearbeitung mit der Hintergrundentfernung, der Textextrahierung, der Zeilensegmentierung und der Wortsegment die Parameter einzustellen, die für Erkennung und Zerlegung der individuellen Handschrift notwendig sind. Dies nennen wir die Kalibrierung der eigenen Handschrift. Diese Parameter sind dann später nicht nur für das Training, sondern auch für das Erkennen des Textes bei einer Vorhersage wichtig.
Sollten die Trainingsseiten auf einem speziellen Untergrund geschrieben worden sein, so ist es wiederum für die Texterkennung notwendig, zunächst über eine oder mehrere unterschiedliche Leerseiten jeweils den Hintergrund heraus zurechnen.
Raimund
26. August 2025 15:35
Aus dieser Überlegung ergibt sich folgendes logische Vorgehen für die Erstellung eines Modells zur Erkennung der eigenen Handschrift:
-
Erfassung der Leerseite(n), auf denen die handschriftlichen Texte geschrieben sind
-
Erfassung der Trainingsseiten und Erstellung von beschrifteten Wortbildern. Dabei kann jeweils eine Leerseite zur Trainingsseite zugeordnet werden, um den Hintergrund heraus zurechnen
-
Dabei Erlernen/Erfahren der Parameter zu Bearbeitung der eigenen Handschrift (Kalibrierung) und Speicherung der Parameter im eigenen Profil
-
So viele Trainingsseiten erfassen und bearbeiten bis 8.000 bis 15.000 Wortbilder vorhanden sind.
-
Erstellung eines Modells und mind. eines Modellstandes. Dabei Auswahl eines Basismodells für das Training (TrOCR-base-handwritten oder TrOCR-large-handwritten).
-
Zuordnung der Trainingsseiten zu einem Modellstand mit Aufteilung in Trainingsdaten und Testdaten (Validierungsdaten).
-
Training des Modells mit den Standardwerten oder Export der zuordneten Trainingsdaten für ein lokales (schnelleres) Training. Anschließend kann das berechnete Modell wieder importiert werden.
-
Konfiguration über Anpassung der Standardparameter zur Nachbearbeitung mit einem LLM (Large Language Modell)
-
Pflege der Schlagwortliste zum Modell, um einen Themenkontext für das LLM zur Verfügung zu stellen.
-
Start mit Deinen eigenen Vorhersagen zu Deiner Handschrift.
Raimund
26. August 2025 19:35
Link zu KI Sauklaue - Einführung