26. August 2025 16:36
KI Sauklaue - Bedienungsanleitung
26. August 2025 16:37
Anmeldung:
Du brauchst einen frei definierbaren User und ein Passwort. Wenn Du noch keinen User hast, registriere Dich einfach (Beachte die einfachen Passwortregeln).
26. August 2025 16:39
Startbildschirm:
Der erste Einstieg in den Startbildschirm sieht sehr aufgeräumt aus. Allein die Buttonleiste mit den elementaren Strukturelementen, Sortierbutton und die Profilpflege von „KI Sauklaue“ fällt auf:

26. August 2025 16:40
Das Projekt KI Sauklaue gliedert sich in drei Hauptstrukturelemente:
-
Modell/Modellstände (Du befindest Dich hier gerade)
-
Trainingsseiten
-
Leerseiten
Zu der Bedeutung und dem Zusammenspiel dieser Elemente siehe „Strukturelemente und Vorgehen zum Einrichten eines eigenen Modells“.
Über diese Buttons springst Du zwischen diesen unabhängigen Strukturelementen. Im Bereich Modell/Modellstände gibt es zusätzlich einen Button für die Einrichtung eines neuen Modells (siehe weiter unten).
26. August 2025 16:41
Mit dem Button Profil (Button mit dem Körper) kannst Du an dieser Stelle die allgemeinen Einstellungen zu Deinem User pflegen, wie etwa Vor- und Nachname, eine E-Mail-Adresse oder Sortiervorlieben.
Insbesondere wenn Du die API-Schnittstelle der KI Sauklaue nutzen möchtest, kannst Du Dir hier einen API Token kostenfrei generieren lassen.
26. August 2025 16:42
Neues Modell anlegen / Bearbeiten Modell:
Über den Button „Neues Modell“ wird ein neues Modell definiert, dass nur eine Bezeichnung benötigt. Über den Button „Bearbeiten“ eines Modells kannst Du die Bezeichnung jederzeit ändern.
Der Status des Modells und der aktive Modellstand wird automatisch auf Basis der zugehörigen Modellstände automatisch gefüllt.
26. August 2025 16:48
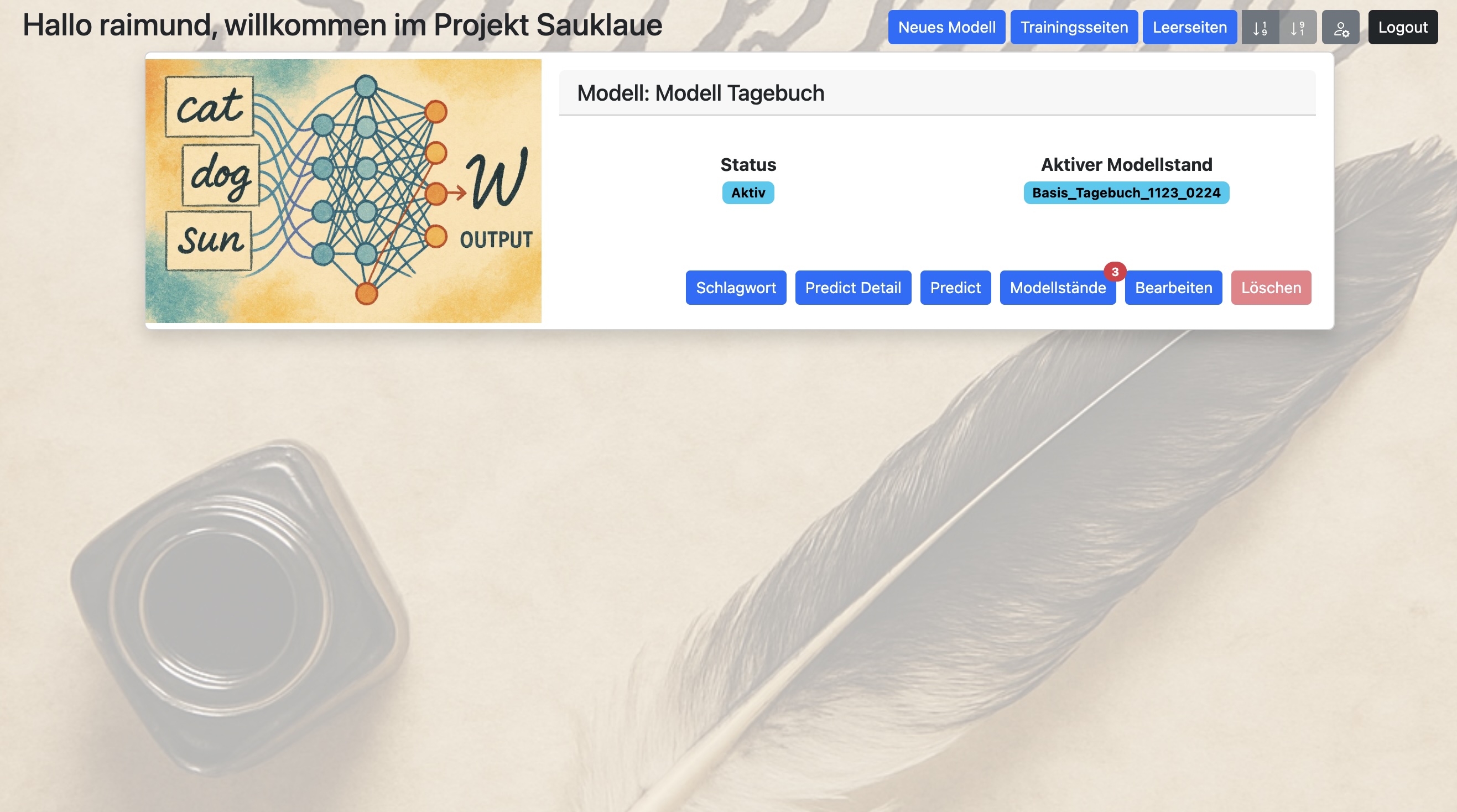
Übersicht Modelle:
Hast Du ein oder mehrere Modelle eingerichtet, so stellt sich der Bildschirm im Bereich Modelle z.B. wie folgt dar:
26. August 2025 16:49
Die Buttons „Predict Detail“ und „Predict” stehen nur zur Verfügung, wenn das Modell aktiv ist, d.h. wenn es zum Modell mindestens einen aktiven Modellstand gibt.
26. August 2025 16:49
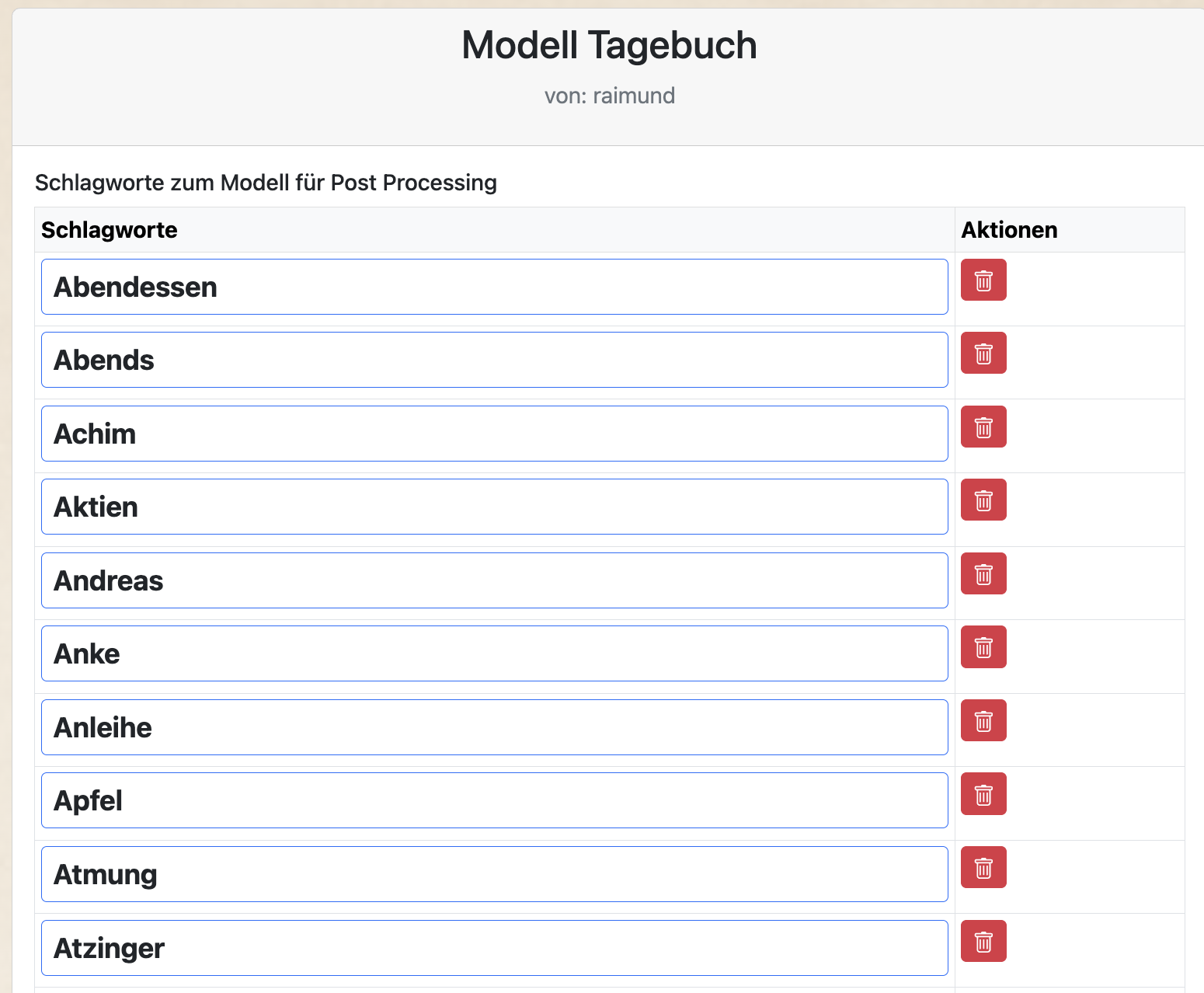
Schlagworte:
Über den Button „Schlagworte“ kannst Du zu dem Modell einen Themenkomplex definieren, in dem Du zum Modell spezifische, wichtige oder häufige vorkommende Begriffe aus Deinem Handschriftenkontext hinterlegst.
Mit diesen Schlagworten hilfst Du im Nachbearbeitungsprozess dem LLM-Modell korrekte Begriffe und Sätze zu bilden, die bisher unsicher geblieben sind:
26. August 2025 16:50
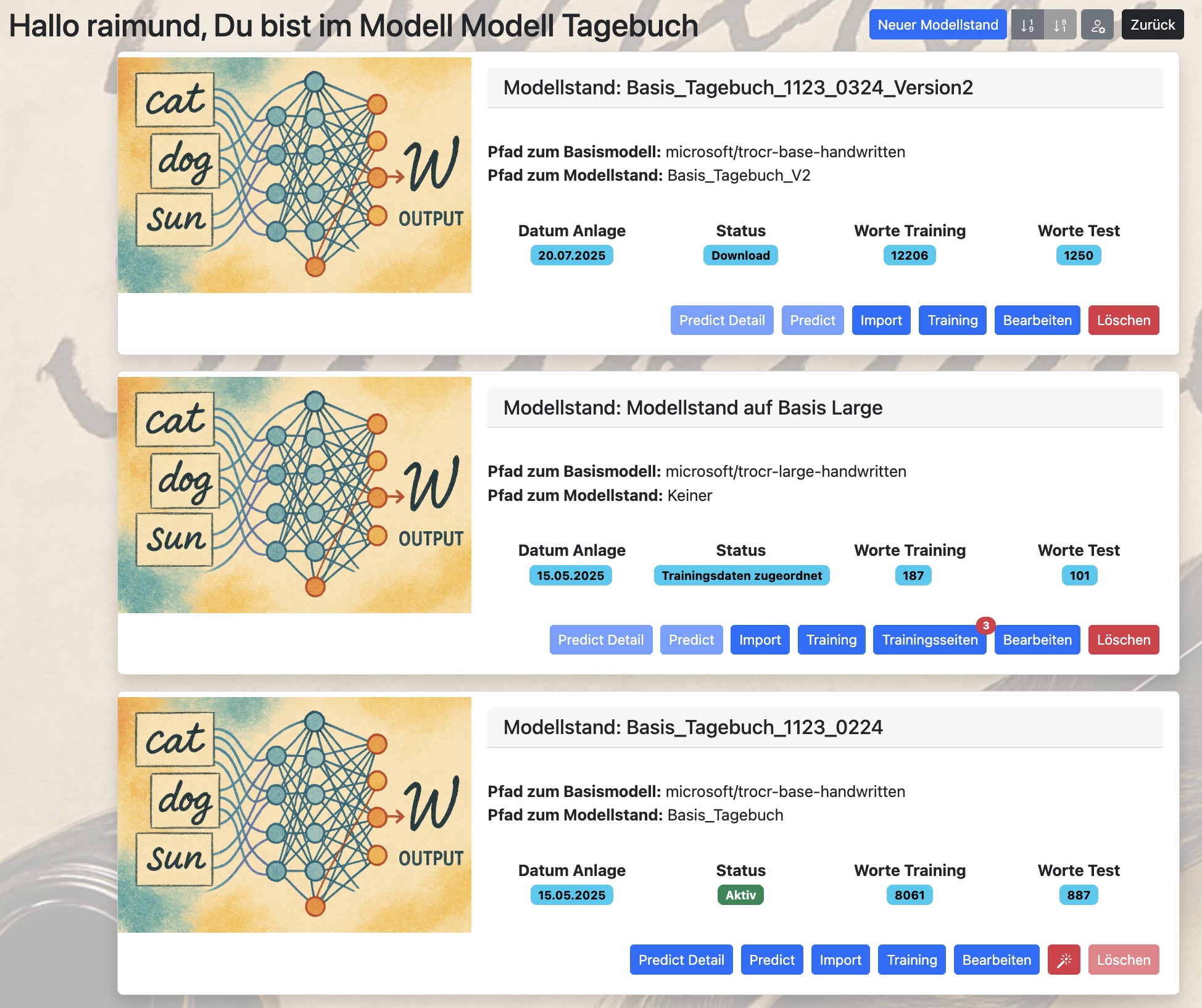
Übersicht Modellstände:
Über den Button „Modellstände“ gelangst Du in die Übersicht in die Modellstände eines Modells. Der Modellstand beinhaltet die eigentliche Definition zu einer Handschrifterkennung mit der Einrichtung zur Kalibrierung Deiner Handschrift, einem mit Deinen Trainingsdaten trainierten TrOCR-Modells und einer Nachbearbeitung über ein Large Language Modell (LLM).
Dabei kann ein Modell beliebig viele Modellstände beinhalten, die zwar zum gleichen Modell und damit zum gleichen Themenkontext gehören, prinzipiell aber unabhängig voneinander funktionieren. Nur im Spezialfall des Curriculum Learning (siehe Beschreibung: Trainieren eines TrOCR-Systems mit Deiner Handschrift) bauen einzelnen Modellstände aufeinander auf.
Jeder Modellstand besitzt,
-
einen Pfad zu einem Basismodell als Grundlage für sein Training
-
einen Pfad zu dem Zielmodell, in dem das trainierte Modell abgelegt ist
-
ein Datum der Anlage
-
ein Status (Offen, Trainingsdaten zugeordnet, Download, Training, Import, Training abgeschlossen, Aktiv, Inaktiv)
-
eine Anzahl zugewiesenen Trainingsseiten als Trainings- oder Testwortbilder
26. August 2025 16:53
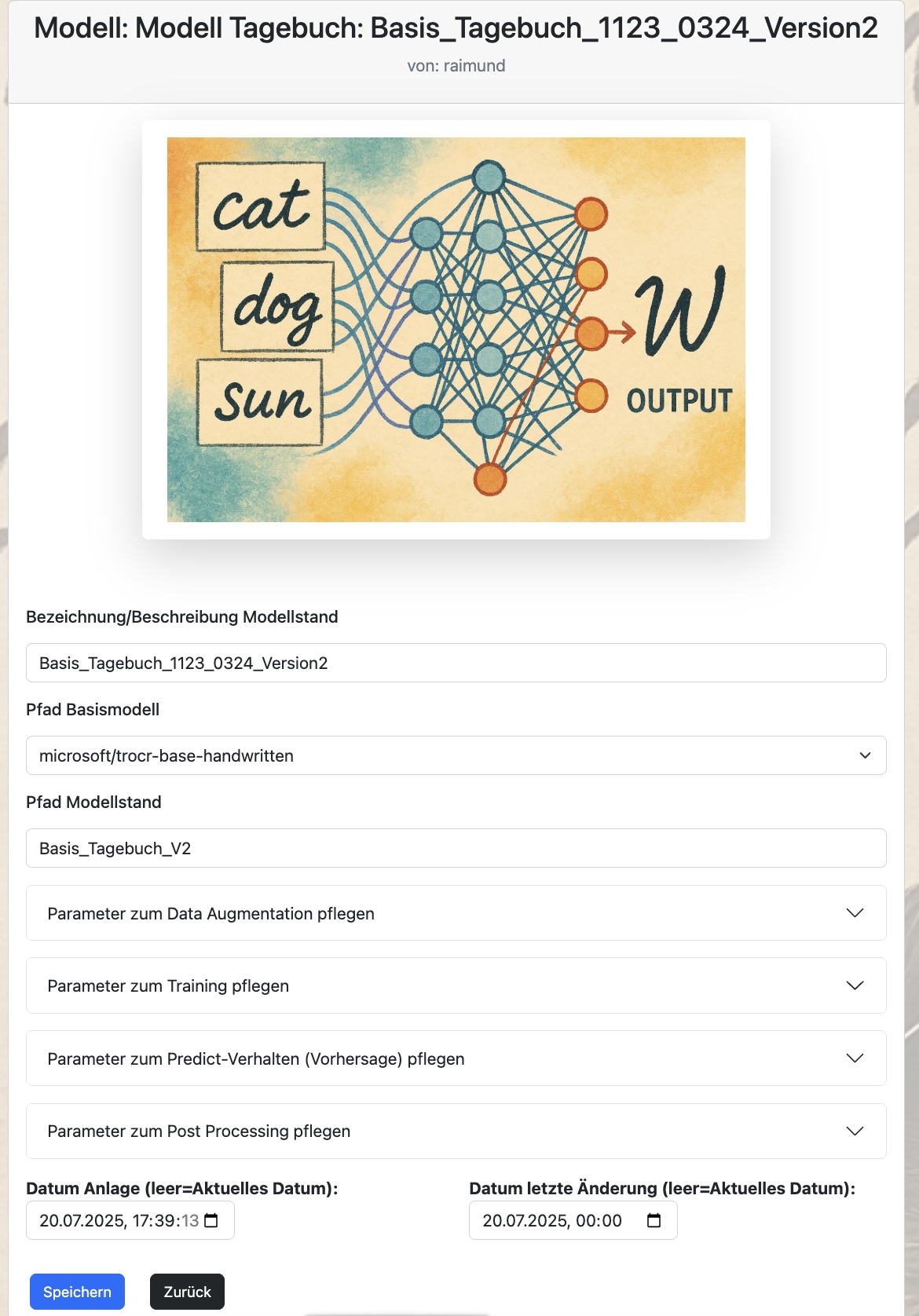
Neuer Modellstand / Pflege der Modellstände:
Bei der Einrichtung bzw. Pflege der Modellstände können neben einer Bezeichnung insbesondere die Pfade zum Basismodell für das Training und der Pfad mit dem Zielverzeichnis des trainierten Modells gepflegt werden.
Weiterhin werden zu einem Modellstand eine ganze Reihe von Parametern eingerichtet, die an dieser Stelle über Untermenüs angepasst werden können.
Dazu gehören Parameter zum
-
Data Augmentation während des Trainings
-
Weiteren Trainingsverhalten
-
Verhalten bei Vorhersagen des TrOCR-Modells
-
Konfigurieren der Nachbearbeitung mit einem LLM-Modell
Für weitere Informationen dazu siehe in „Trainieren eines KI Sauklaue-Modells mit Deiner Handschrift„ und „Funktionen und Techniken zur Vorhersage und Post-Processing“.
26. August 2025 16:54
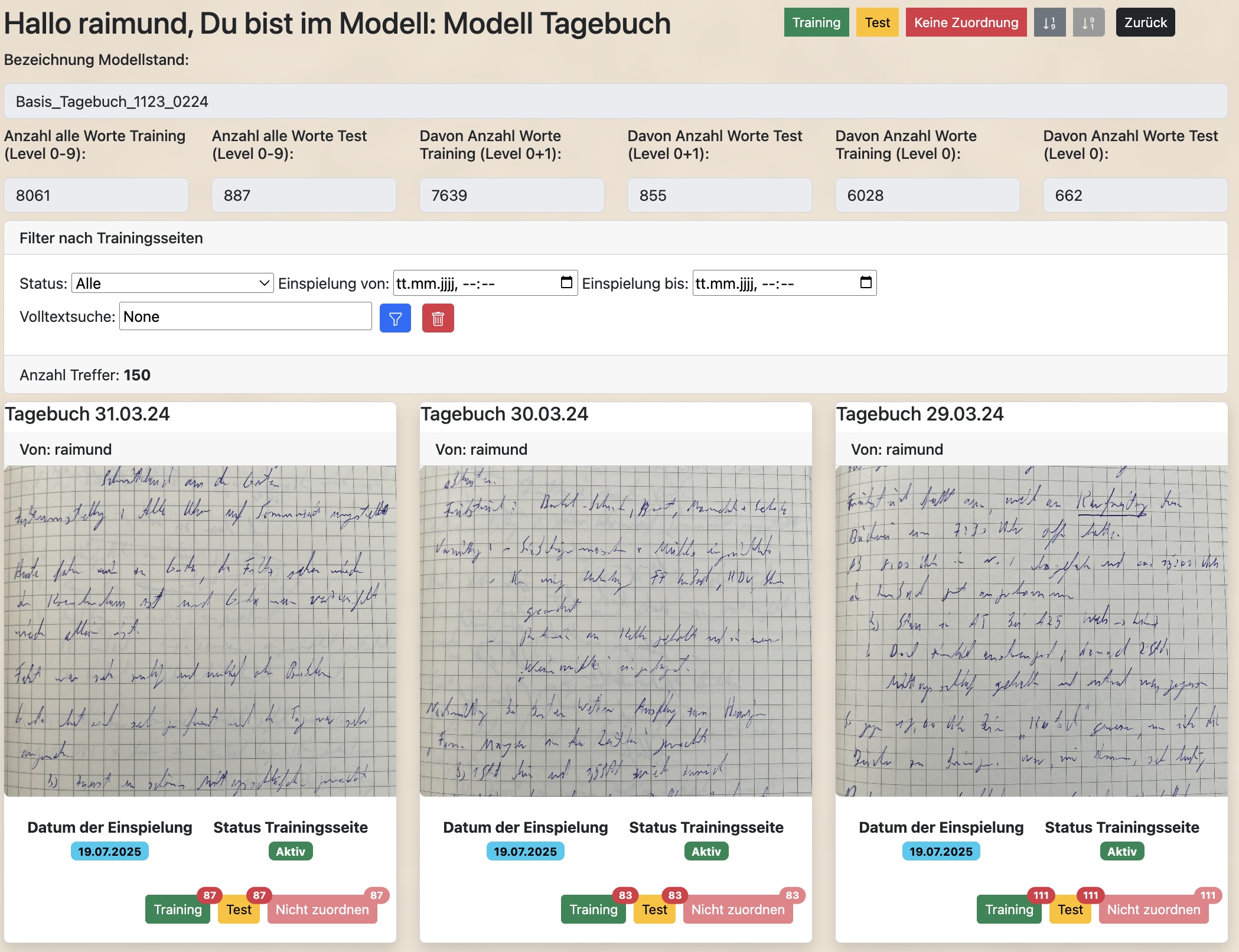
Zuordnung/Pflege Trainingsseiten zum Modellstand:
Ohne die Zuordnung von Wortbildern zum Training und Testen kann ein TrOCR-Modell in einem Modellstand nicht trainiert werden. Die Zuordnung von Trainingsseiten zum Modellstand stellt also eine Grundlage für das Training des TrOCR-Modells dar.
Ist ein Modellstand im Status „Offen“ oder „Trainingsdaten zugeordnet“ können dem Modellstand über den Button „Trainingsseiten“ Trainingsseiten zugeordnet werden bzw. diese Zuordnungen gepflegt werden:
26. August 2025 16:56
Dabei werden alle zur Verfügung stehenden Trainingsseiten (Status „Worte segmentiert“ oder „Aktiv“) angezeigt. Über eine Selektion nach verschiedenen Kriterien kannst Du diese Anzeige spezifizieren.
Über die jeweiligen Buttons „Training“, „Test“ oder „Nicht zuordnen“ kann für eine Trainingsseite definiert werden, ob deren Wortbilder dem Modellstand für ein Training zugeordnet wird oder nicht und ob in der Funktion als Trainingsdaten oder in der Funktion als Test-/Validierungsdaten.
In der oberen Buttonreihe kann auch definiert werden, was mit allen selektierten und nicht geordneten Trainingsseiten gesehen soll (Zuordnung als Trainingsdaten oder als Testdaten) bzw. ob alle bereits zugeordneten Trainingsseiten wieder deaktiviert werden sollen.
Zur Übersicht wird immer die Anzahl der zugeordneten Wortbilder als Trainings- oder Testdaten angezeigt. Man sollte bei der Zuordnung darauf achten etwa ein Verhältnis von 85% Trainingsdaten und 15% Testdaten zu besitzen.
Die Wortbilder für das Trainieren und Testen werden zusätzlich nach Wortlevel unterschieden (siehe auch Bearbeiten Trainingsseite):
-
Wortlevel 0: Nur Standard-Schriftsatz
-
Wortlevel 0+1: Zusätzlich auch komplizierte Worte und Schreibweisen
-
Wortlevel 0-9: Alle Wortbilder, auch extreme und sehr spezifische Fälle
26. August 2025 16:57
Trainieren des TrOCR-Modells
Sind einem Modellstand Trainingsdaten zugeordnet, kann mit dem Training des TrOCR-Modells (Pfad zum Basismodell) begonnen werden. Dabei kann das Training prinzipiell auch immer wieder neu gestartet werden, wobei vorhergehende Ergebnisse zu Trainingsläufen aber gelöscht werden.
Über den Button „Training“ gelangt in den Funktionsbereich zum Training seines Modellstandes. Das Training selbst erfolgt dabei immer über einen im Hintergrund laufenden Trainingslauf, der je nach Umfang und Parametern zum Training, zwischen 15 – 60 Stunden andauern kann.
Die Pflege der Parameter zum Trainieren erfolgt in der Pflege des Modellstands. Siehe dazu auch Trainieren eines KI Sauklaue-Modells mit Deiner Handschrift
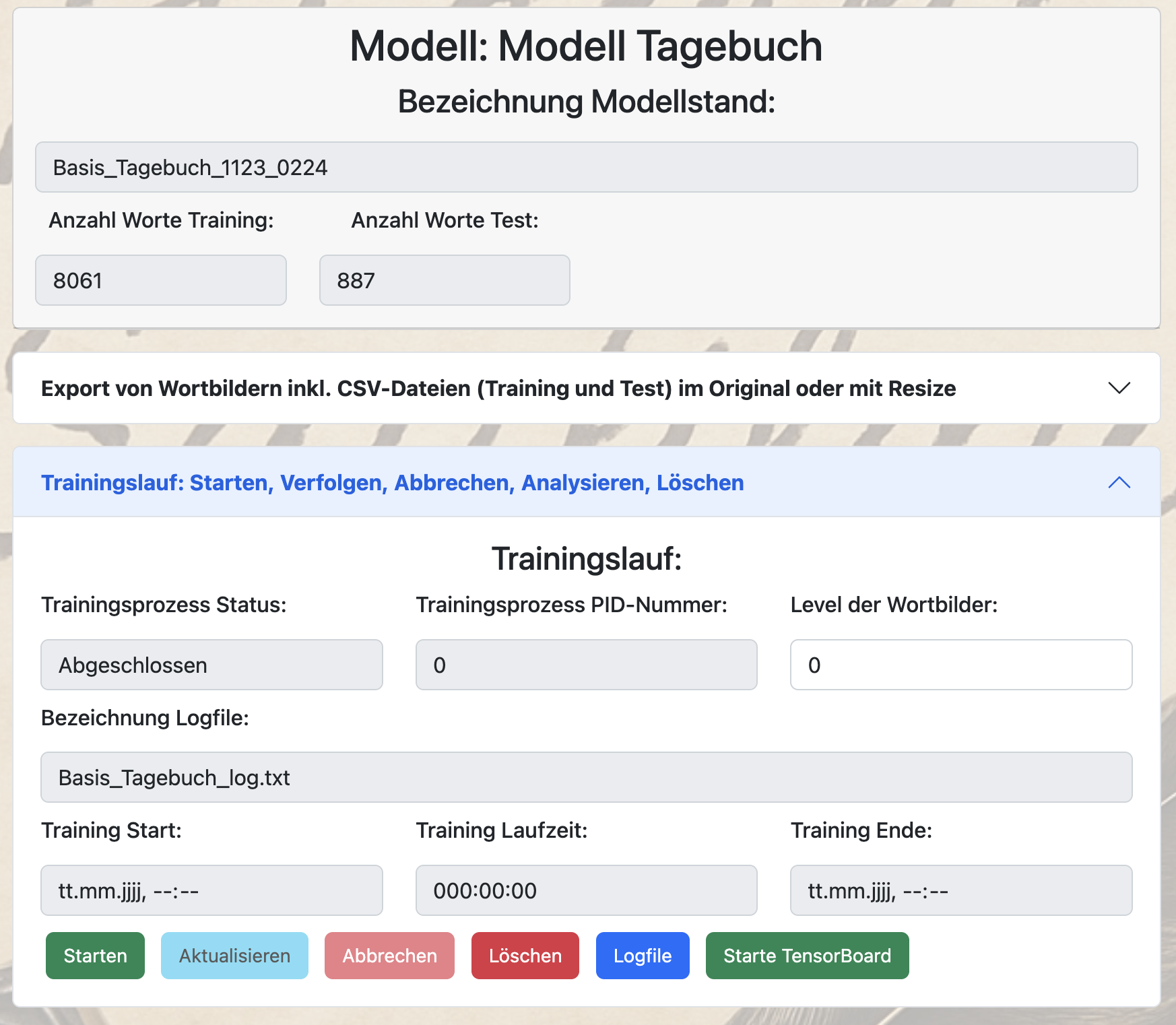
Mit den Funktionen zum Trainieren kann man einen Trainingslauf einrichten, verfolgen, abbrechen, analysieren oder löschen.
Zum Trainingslauf werden immer alle zugeordneten Wortbilder zum Training und Testen in den Trainingslauf übergeben. Lediglich über die Angabe des maximalen Wortlevels (0, 1, 9) kann man noch definieren, ob nur der Standard-Schriftsatz (0), oder auch komplexere Wortbilder (1) oder alle Wortbilder (9) am Trainingslauf teilnehmen sollen.
26. August 2025 16:59
Mit dem Button „Starten“ wird ein Hintergrundlauf mit dem Training gestartet. Dabei wird eine Prozess-ID (PID) vergeben und ein Logfile eingerichtet.
Über die Zeitpunkte zum Trainingsstart, Trainingsende und Trainingslaufzeit, sowie über den Status des Trainingsprozesses kann nun nachvollzogen werden, ob und wie das Training zum Modellstand aktuell läuft. Über den Button „Aktualisieren“ werden diese Angaben während des Trainingslauf auf den neuesten Stand gebracht.
26. August 2025 16:59
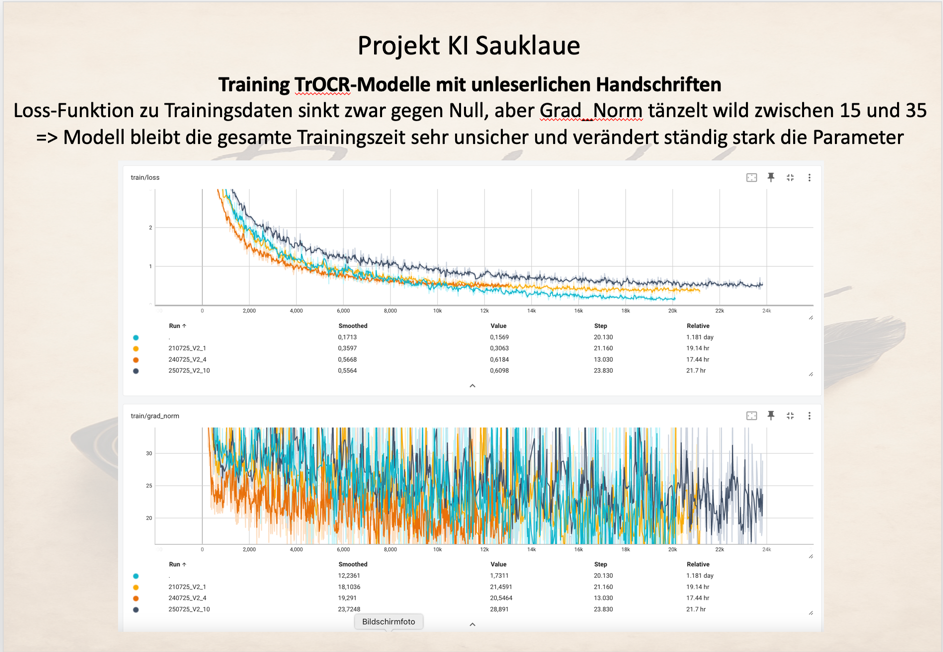
Genauere Angaben zu einem Trainingslauf geben das fortlaufende aktualisierte Logfile und das Tensorboard mit der Auswertung der Laufzeitparameter zum Training.
Gerade über das Tensorboard können die wichtigen Parameter, wie Train-Loss-Funktion, Eval-Loss-Funktion, Grad-Norm-Funktion, CER-Wert, WER-Wert uvm., die über den Erfolg des Trainings Auskunft geben, kontrolliert werden.
Beispiel einer Tensorboard-Auswertung:
26. August 2025 17:02
Ein Trainingslauf kann aber auch abgebrochen werden, wenn die Ergebnisse aus dem Logfile oder der Tensorboard-Analyse ein falsches Trainingsverhalten erkennen lassen.
Natürlich kann ein Trainingslauf über den Button „Löschen“ auch komplett entfernt werden.
26. August 2025 17:03
Export von Trainingsdaten, Download von TrOCR-Modellen, Import von TrOCR-Modellen
Es sei an dieser Stelle angemerkt, dass auf dem aktuell vorhandenen Server auf dem KI Sauklaue im Internet zur Verfügung steht, die Laufzeiten sehr langsam sind.
Daher ist es in vielen Fällen für fortgeschrittene Anwender empfehlenswerter die Trainingsdaten lokal zu exportieren, das Training damit lokal am besten auf einer für KI Training spezialisierten Maschine durchzuführen und nur das Ergebnis des Trainings wieder in das Projekt „KI Sauklaue“ zu importieren.
Für weniger versierte User wenden Sie sich bitte an den Administrator, um Sie bei einem lokalen Training zu unterstützen.
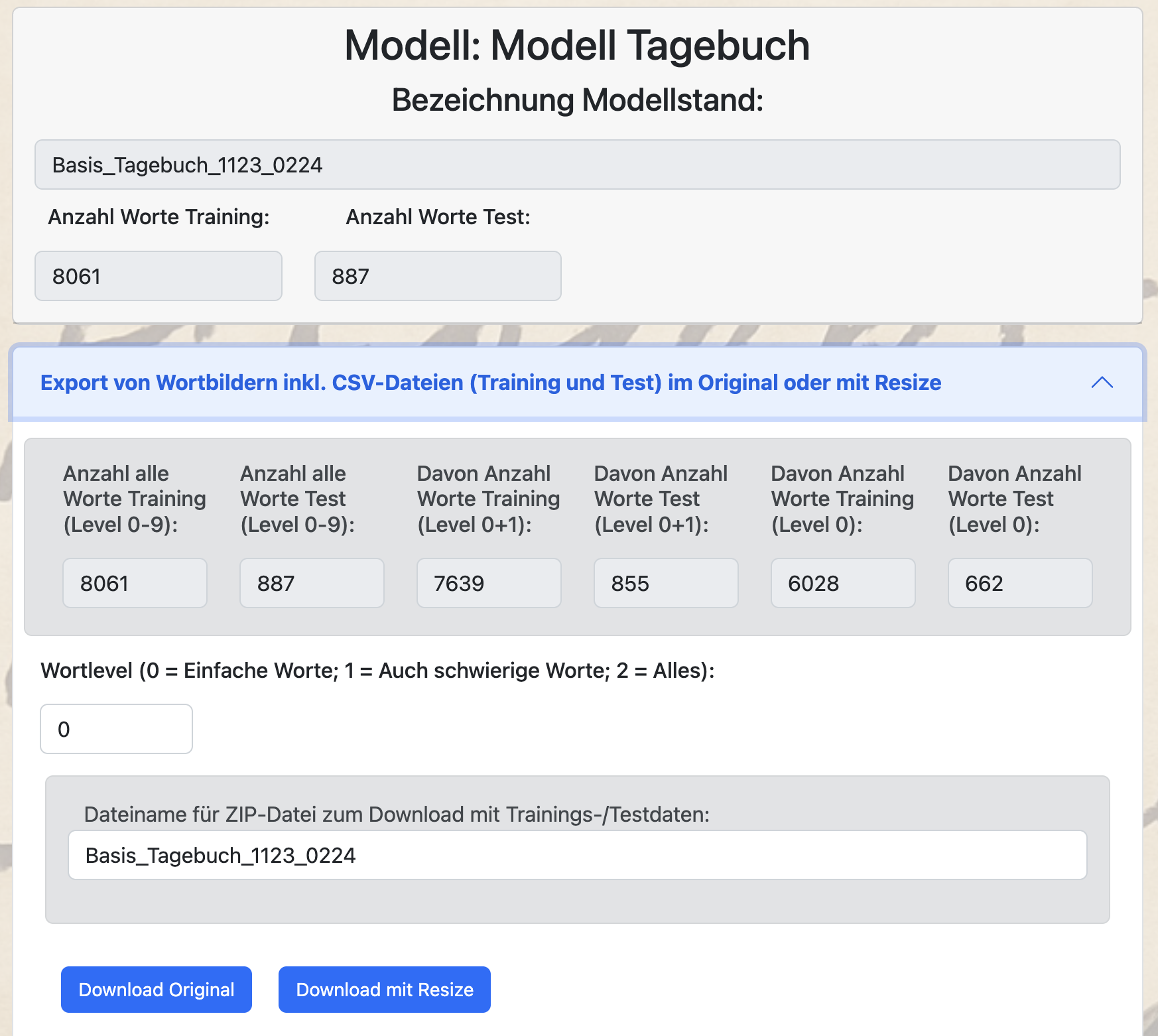
Um dem Modellstand zugeordnete Wortbilder als Trainingsdaten und Testdaten in der notwendigen Form zu exportieren, steht im Bereich „Training“ das Untermenü „Export von Wortbildern“ zur Verfügung.
Dabei werden jeweils CSV-Dateien mit den jeweiligen Wortbildern und deren Beschreibung für die Trainingsdaten und für die Testdaten erzeugt. Weiterhin werden getrennt nach Training und Test Unterverzeichnisse mit den entsprechenden Wortbildern erzeugt.
Alle Daten werden in einer ZIP-Datei exportiert, wobei über die Buttons „Download Original“ oder „Download mit Resize“ noch entschieden werden kann, ob die Wortbilder in ihrer Originalgröße oder mit einer angepassten und standardisierten Wortbildgröße entsprechend der Parameter aus dem Modellstand exportiert werden sollen.
Es wird dabei explizit empfohlen die Wortbilder mit einem Resize auf 384x384 Pixel im Padding-Verfahren zu exportieren.
26. August 2025 17:05
Mit diesen Daten kann dann das Training lokal durchgeführt werden.
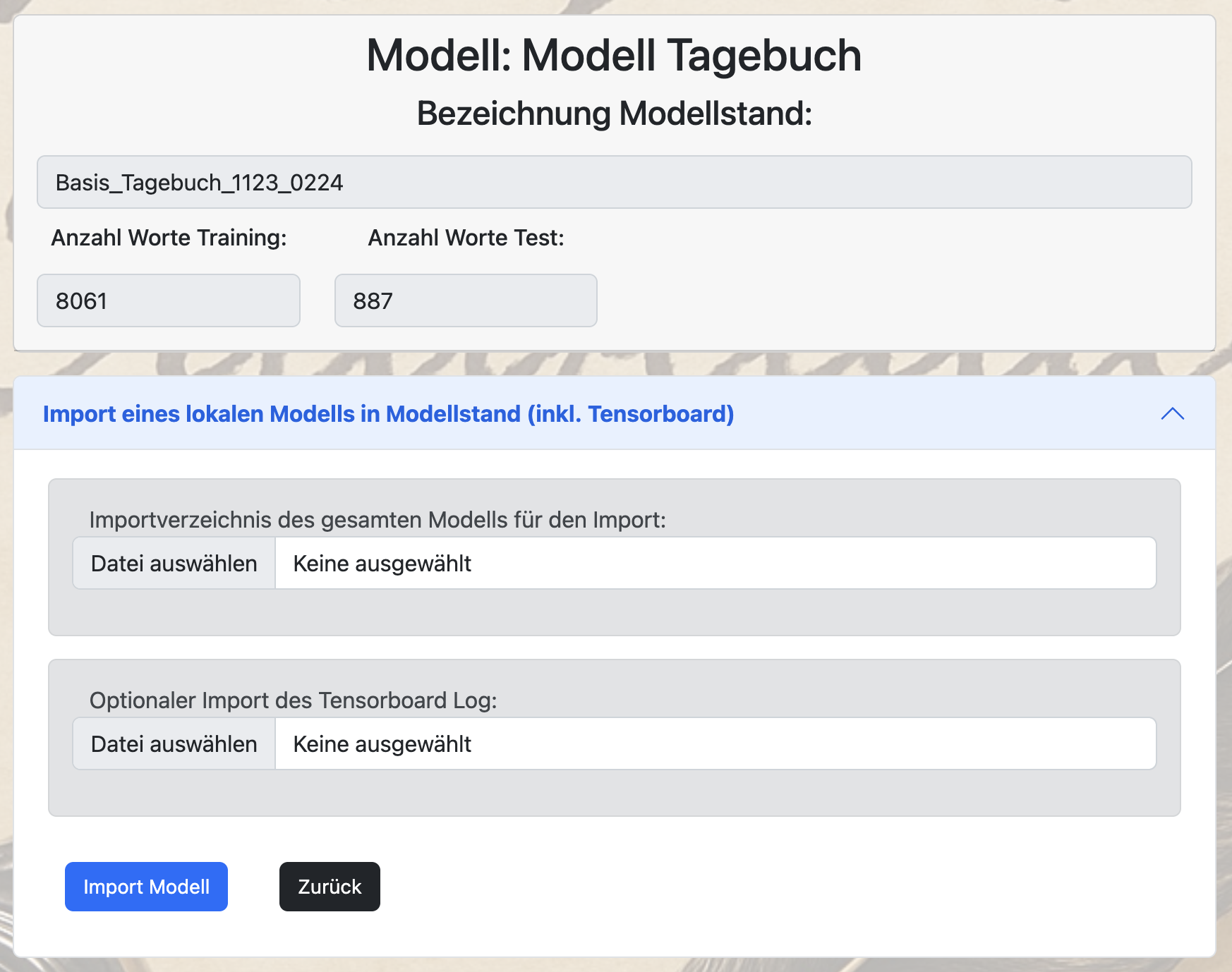
Das fertig trainierte neue TrOCR-Modell kann dann zu einem Modellstand über den Button „Import“ in der Übersicht der Modellstände eingespielt werden.
Dabei kann neben dem Verzeichnis mit dem neuen Modell auch das Tensorboard Log für anschließende Analysen für den Import angegeben werden:
26. August 2025 17:07
Wenn man aber die langen Laufzeiten auf dem Server nicht scheut, kann man das Training aber auch, wie beschrieben, auf dem Server durchführen.
Im Zusammenspiel mit lokalen Anwendungen besteht dann auch die Möglichkeit, dass auf dem Server trainierte TrOCR-Modell lokal herunterzuladen. Dazu steht im Bereich „Training“ das Untermenü „Download von Modell inkl. Logs, Tensorboard, Worte als Zip-File zur Verfügung“
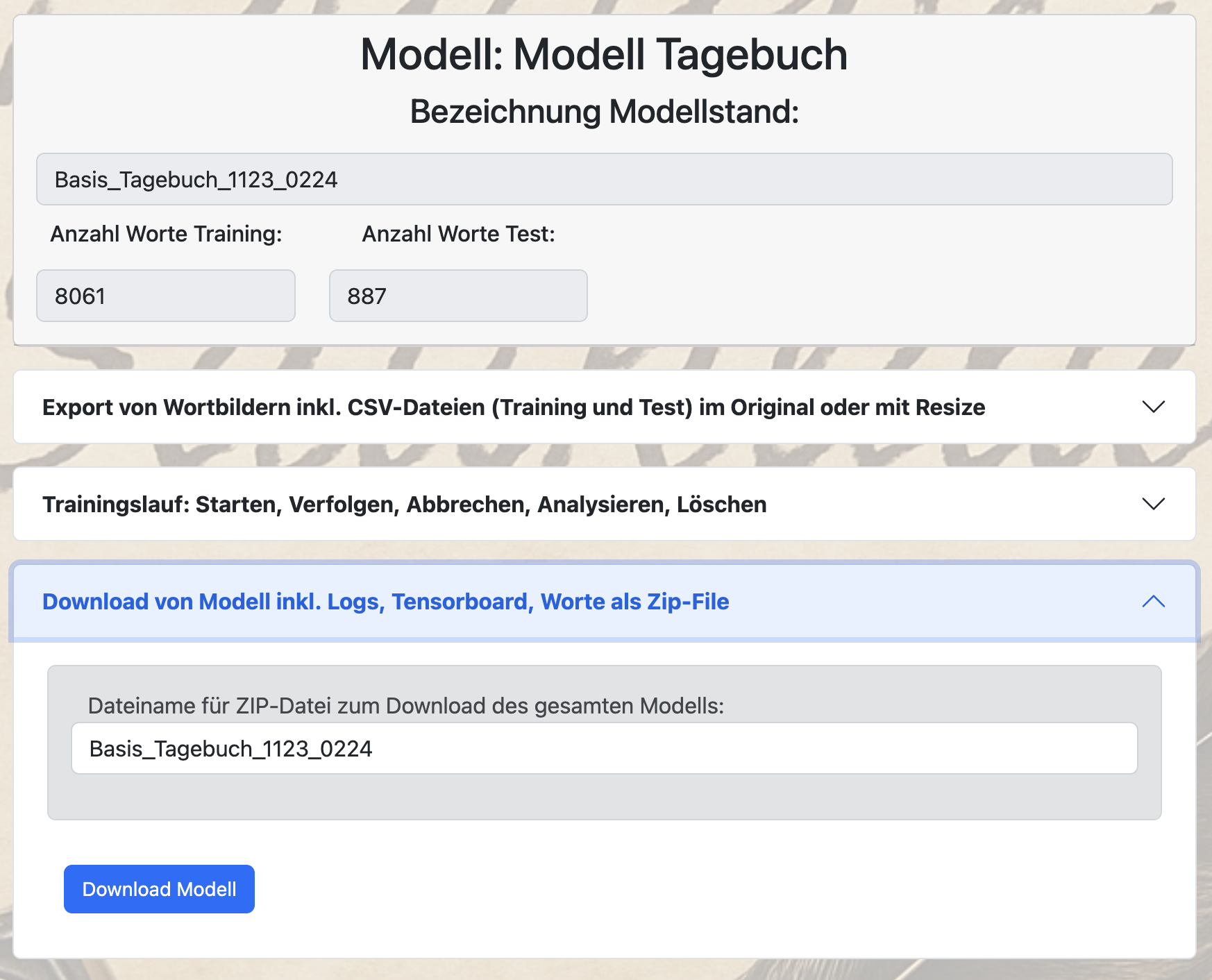
26. August 2025 17:09
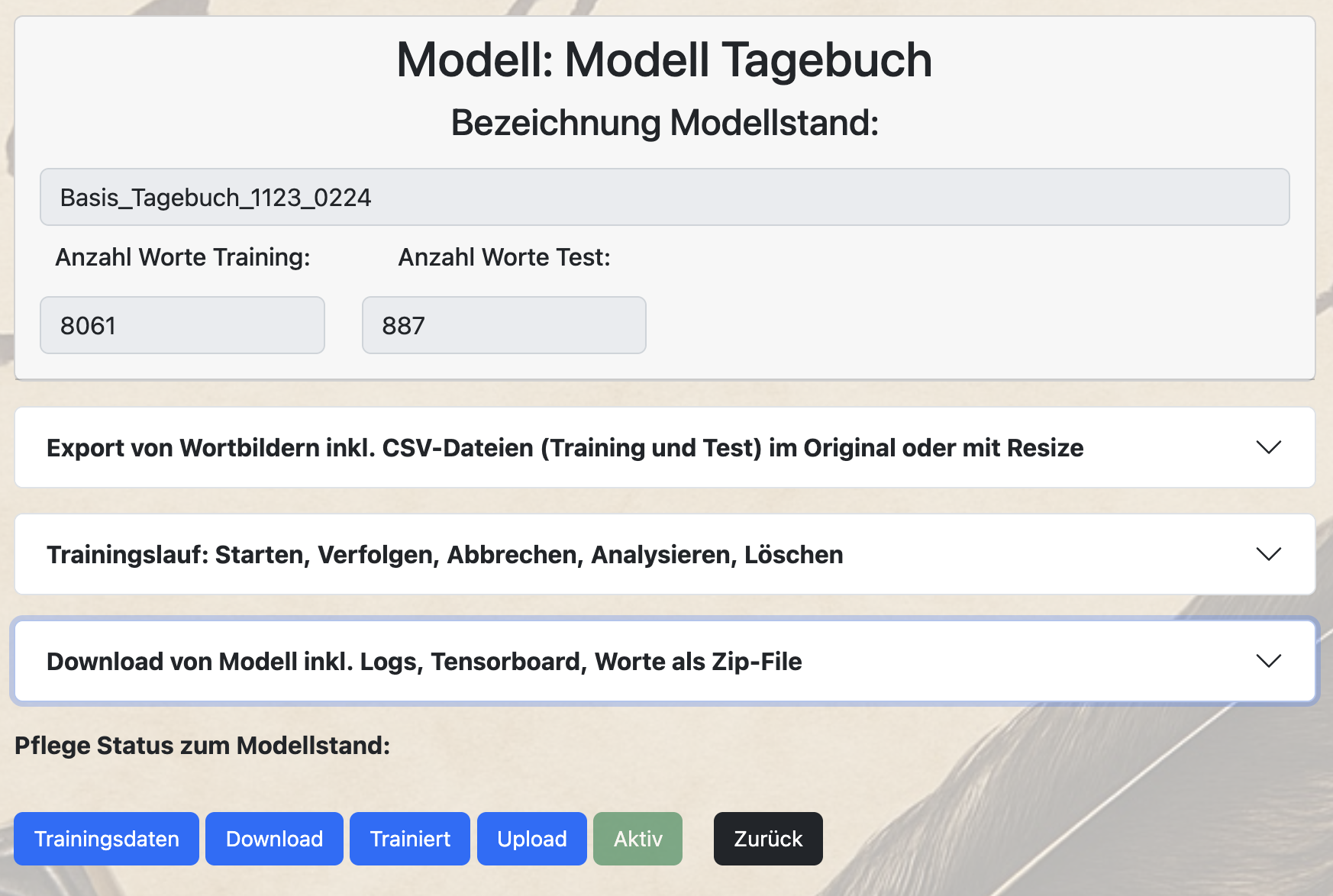
Pflege des Status zu einem Modellstand
Im Bereich „Training“ wird letztlich festgelegt, in welchem Status sich ein Modellstand befindet:
26. August 2025 17:11
Erst nach einem erfolgreichen Training oder einem Import kann ein Modellstand in den Status „Aktiv“ gesetzt werden.
Nur zu einem aktiven Modellstand können Vorhersagen (Predict) und damit eine echte Handschriftenerkennung durchgeführt werden.
Über die anderen Buttons „Trainingsdaten“, „Download“, „Trainiert“, „Upload“ wird der Modellstand in den jeweiligen Status zurückgesetzt.
26. August 2025 17:12
Vorhersagen mit einem Modellstand (Predict) und (Predict Detail)
Wenn ein Modellstand trainiert oder ein trainiertes TrOCR-Modell importiert wurde und in den Status „Aktiv“ gesetzt wurde, kann es mit der eigentlichen Erkennung Deiner Handschriften losgehen.
Dazu gibt es zum Modellstand die Funktionen „Predict“ und „Predict Detail“. Diese Funktionen stehen auch auf der Ebene des Modells zur Verfügung, wenn es mindestens einen aktiven Modellstand besitzt. Gibt es mehrere aktive Modellstände wird für das Modell immer der neueste aktive Modellstand genutzt.
Bei Predict musst Du nur minimale Angaben machen:
-
das Foto mit Deiner Handschrift,
-
einem Typ der zu erkennenden Handschrift (Seite mit Hintergrund, Seite mit Textextrahierung, Seite mit reinem Text, Zeile, Wort)
-
Nur beim Typ „Seite mit Hintergrund“ muss dann noch im Projekt KI Sauklaue vorhandene Leerseite (als Vorlage für den Hintergrund) ausgewählt werden.
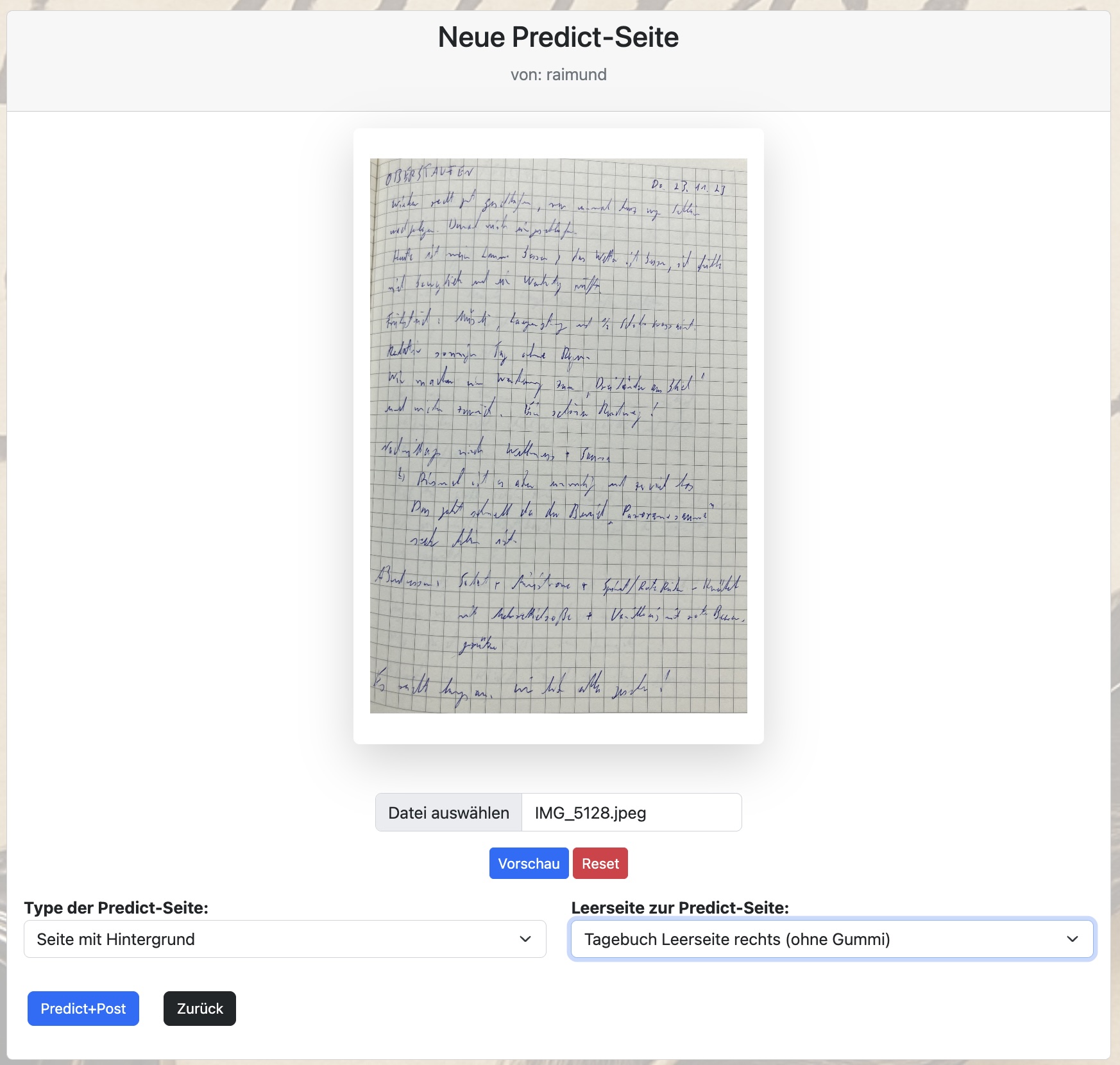
26. August 2025 17:14
Über den Button „Predict+Post“ wird das Foto und die anderen Angaben entgegengenommen und Deine Handschrift sowohl durch das TrOCR als auch durch die Nachbearbeitung mit einem LLM-Modell erkannt.
Das Ergebnis kannst Du dann als neue Predict-Seite in „Predict Detail“ betrachten.
26. August 2025 17:15
Predict Detail
Deutlich mehr Möglichkeiten, um mit Deinen handschriftlichen Texten zu arbeiten, finden sich auf der Oberfläche von „Predict Detail“.
In Predict Detail werden Dir alle gespeicherten Vorhersagen zu einem Modellstand aufgelistet. Es gilt für alle Vorhersagen, ob aus Predict, Predict Detail oder dem externen Zugriff über die API-Schnittelle:
Alle Vorhersagen werden dauerhaft gespeichert und können auf dieser Oberfläche analysiert, korrigiert, nachbearbeitet oder auch wieder gelöscht werden:
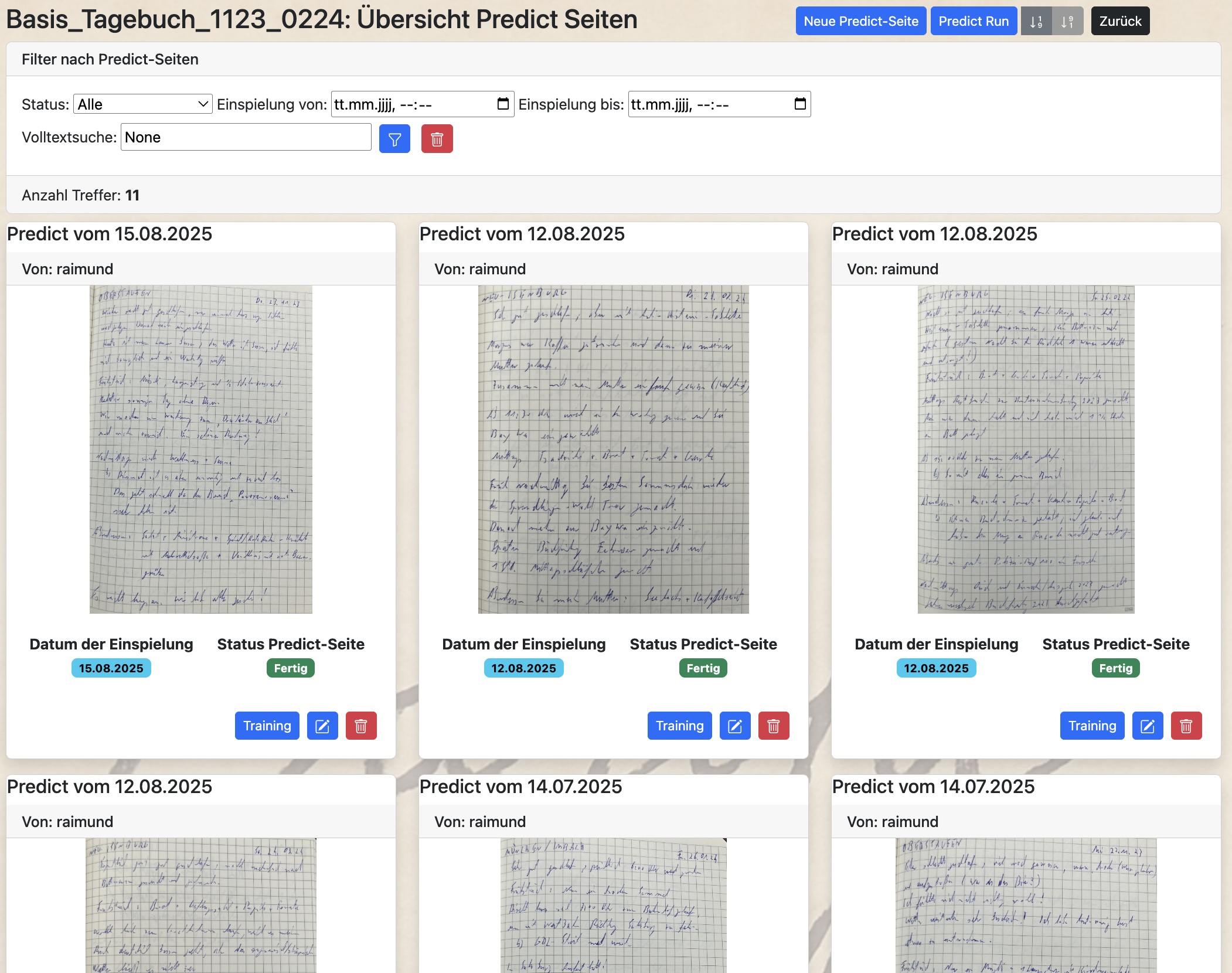
26. August 2025 17:17
Über die Funktion „Neue Predict Seite“ können auch auf dieser Oberfläche neue Fotos zu analysierenden Handschriften erfasst und gespeichert werden.
Über die Funktion „Bearbeiten“ kommst Du in die Details zu jeder Vorhersage:
26. August 2025 17:19
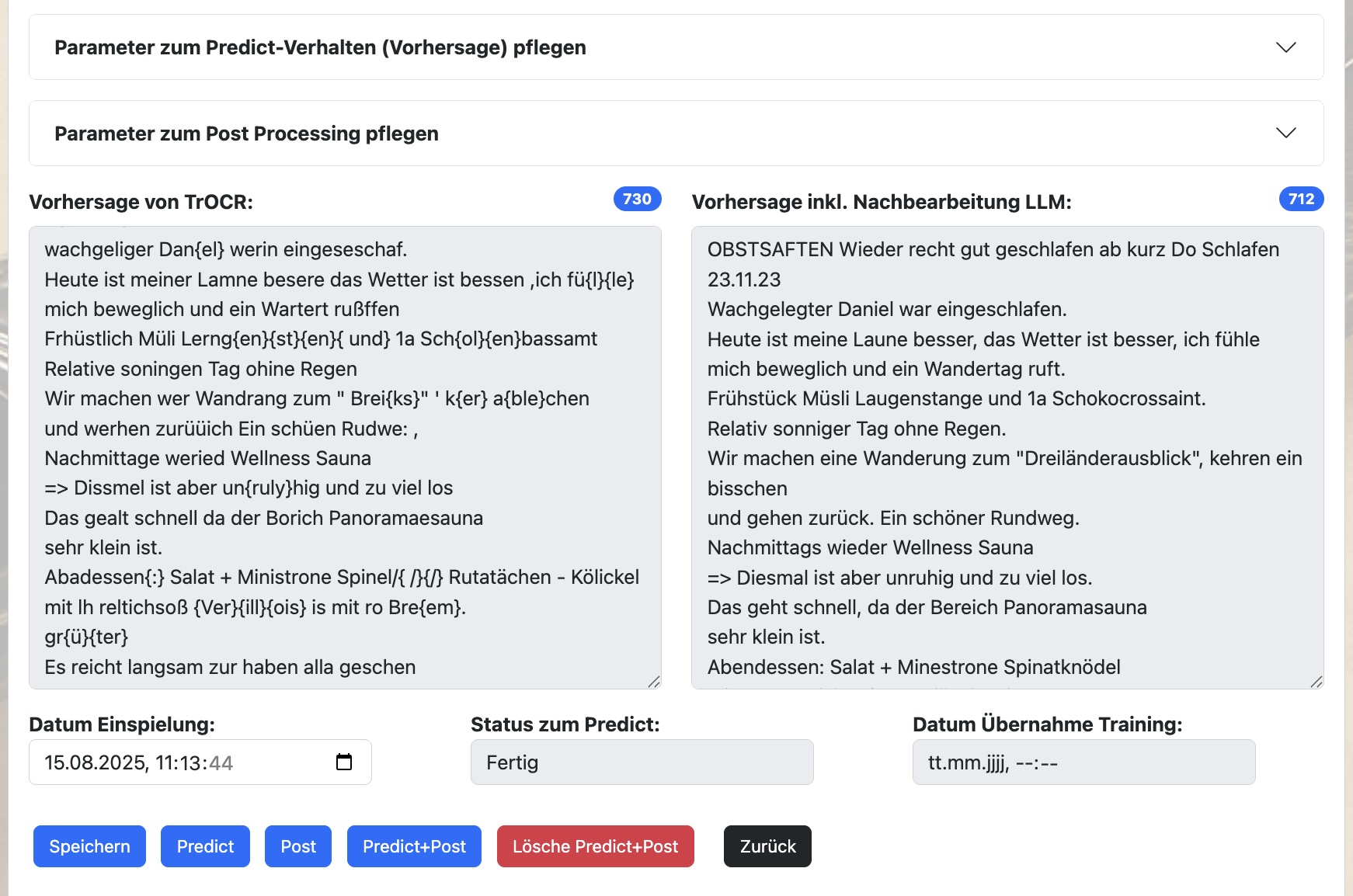
Hier werden Dir die erkannten Texte in zwei Stufen im Detail vorgestellt.
Der Text „Vorhersage von TrOCR“ enthält den reinen Text, der aus dem trainierten TrOCR-Modell gekommen ist. Texte in geschweiften Klammern stellen dabei sehr unsichere Annahmen des Modells dar.
Der Text „Vorhersage inkl. Nachbearbeitung LLM“ stellt dann den finalen Text nach einer Nachbearbeitung durch ein LLM, wie z.B. ChatGPT, dar. Hier fließen dann semantische Zusammenhänge aus dem Satzkontext und auch die Begriffe einer Schlagwortliste in die Nachbearbeitung ein.
Das Verhalten bei einer Vorhersage und bei der Nachbearbeitung kannst Du über zahlreiche Parameter in den Untermenüs „Parameter zum Predict-Verhalten (Vorhersage) pflegen“ und „Parameter zum Post Processing pflegen“ beeinflussen. Siehe dazu die Dokumentation „Funktionen und Techniken zur Vorhersage und Post-Processing“
Über die Funktionen „Predict“, „Post“, „Predict+Post“ und „Lösche Predict+Post“ kannst die Vorhersagen und Nachbearbeitungen erneut durchlaufen lassen oder löschen.
26. August 2025 17:20
Übernahme Predict als Trainingsseite
Ist ein Predict von guter Qualität und willst Du Dein Modell weiter verbessern, so kannst Du eine fertige Predict Seite über den Button „Training“ in der Übersicht von „Predict Detail“ einfach als Trainingsseite übernehmen.
Dabei wird automatisch das Foto und der finale Text aus der Vorhersage inkl. Nachbearbeitung als erste Stufe in der Bearbeitung der Trainingsseite übernommen.
In der Pflege der Trainingsseiten musst Du nun nur noch in gewohnter Weise, die restlichen Schritte bis zur Erstellung der beschrifteten Wortbilder durchführen.
26. August 2025 17:20
Predict Runs
Wenn Du viele Fotos mit Deiner Handschrift erkennen lassen willst, kann dies ziemlich viel Zeit benötigen. Gerade in einer schwachen Serverumgebung kann eine Vorhersage inkl. Post Prozessing schon mal eine Minute oder länger benötigen.
Hier kommen nun die Funktionalität der Predict Runs ins Spiel. Die Idee ist dabei die einzelnen Fotos zur Vorhersage nur innerhalb von Predict Detail nur zu erfassen und zu speichern, aber keinen Predict und kein Post Processing laufen zu lassen.
Vielmehr wird nach der Erfassung aller Predict Fotos in der Übersicht der Button „Predict Run“ gedrückt. Damit gelangst Du in eine neue Übersicht mit vorhandenen „Predict Runs“:
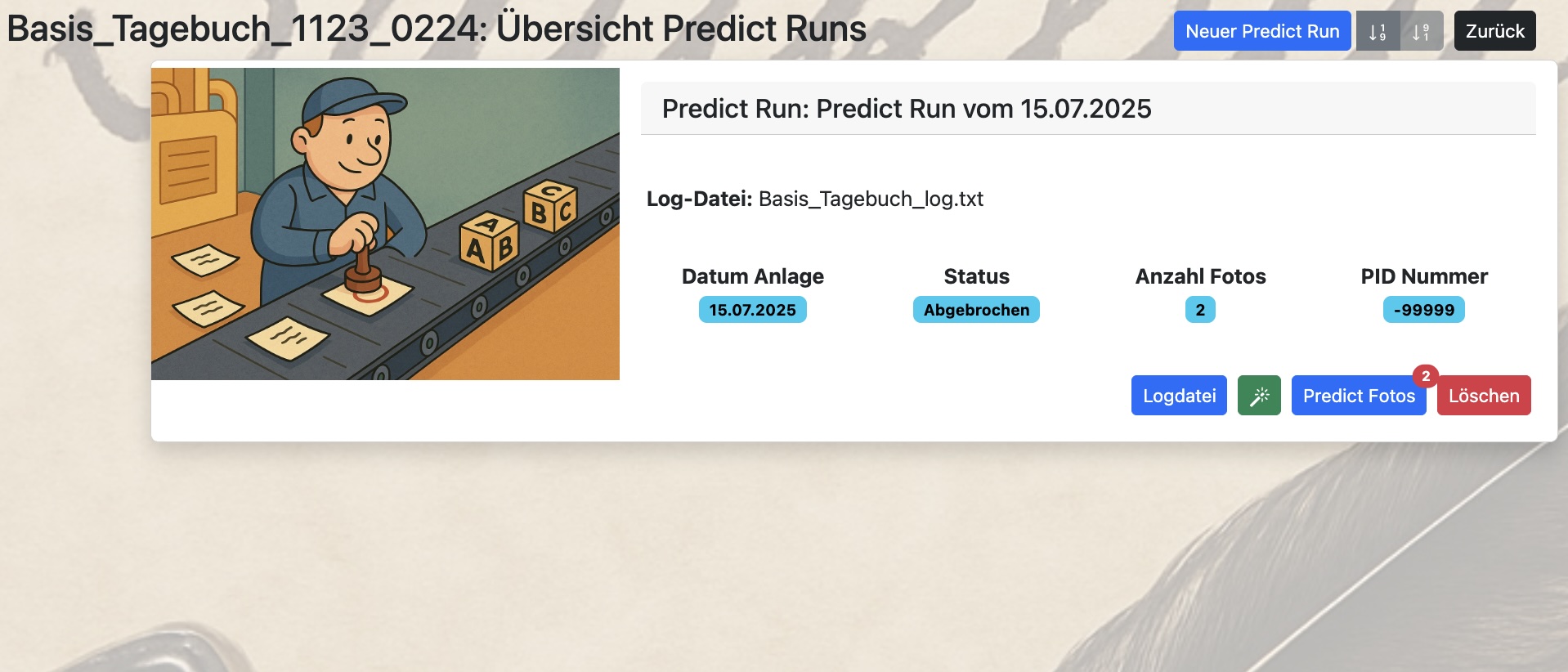
26. August 2025 17:22
Ein Predict Run ist dabei ein Batch-Job, dem automatisch alle zum Zeitpunkt der Erstellung noch nicht final bearbeiteten Predict Fotos zugeordnet werden.
Über den Button „Neuer Predict Run“ wird automatisch ein neuer Predict Run eingerichtet und alle noch nicht „fertigen“ Predict Fotos zugeordnet.
Über den Button „Start“ kannst Du den Batchlauf starten. Er erzeugt einen Hintergrundprozess mit einer eigenen Prozess ID (PID) und arbeitet nun selbstständig alle zugeordneten Predict Fotos ab.
Währenddessen kannst Du ganz normal online weiterarbeiten. Lediglich die zugeordneten Predict-Fotos haben nun den Status „Predict Run zugeordnet“ und stehen Dir während des Laufes des Batchjobs zur Bearbeitung nicht zur Verfügung.
Wenn der Job fertig ist, kannst Du Dir die Ergebnisse unter dem jeweiligen Predict Foto betrachten. Weiterhin wird zu jedem Predict Run eine Logdatei erzeugt, die Du über den Button „Logdatei“ einsehen kannst.
Natürlich kannst Du jederzeit einen Predict Run auch wieder über den Button „Abbruch“ abbrechen.
26. August 2025 17:23
Über die Funktion „Predict Fotos“ kannst Du auch im Vorfeld prüfen, welche Predict Fotos dem Predict Run zugeordnet wurden:
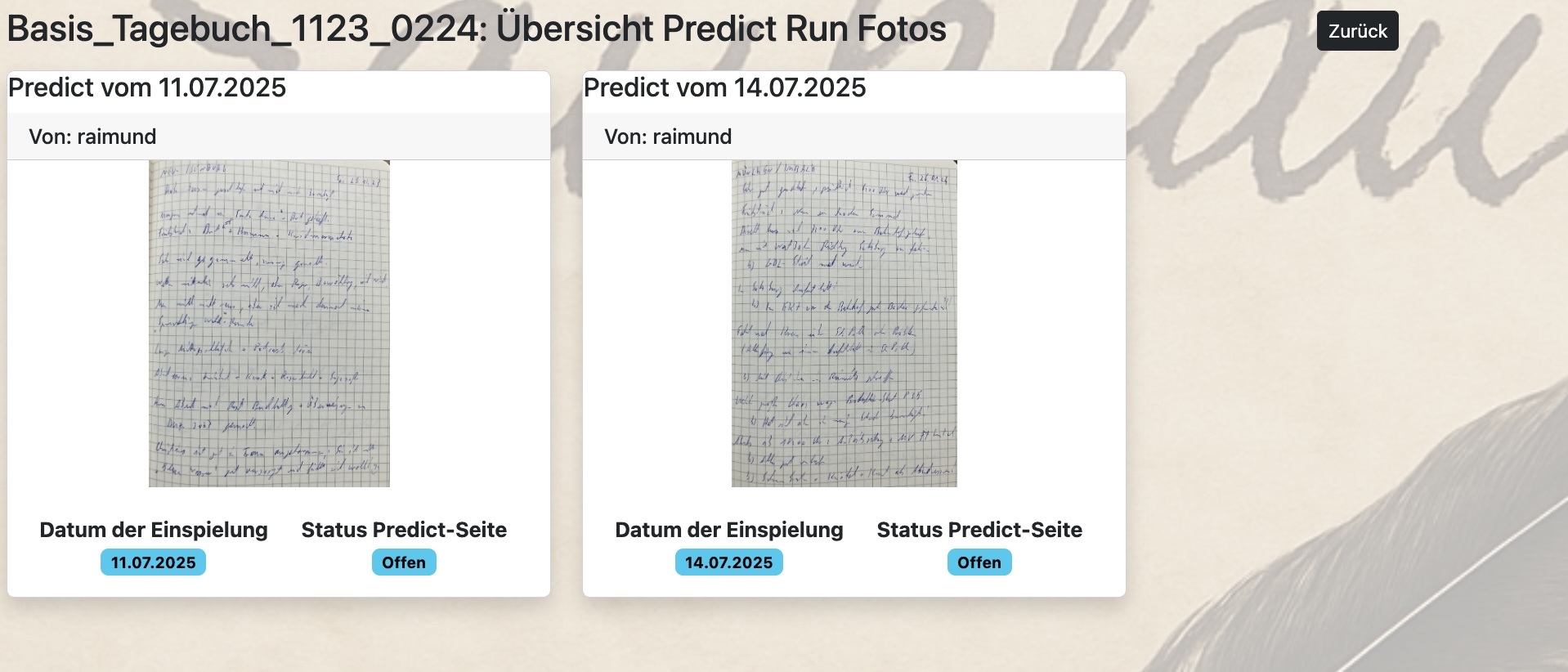
26. August 2025 17:25
Die Trainingsseiten
Ohne Trainingsdaten kein Training eines TrOCR-Modells. Bevor mit einem Modell oder Modellstand eine Vorhersage getroffen werden kann, muss das TrOCR-Modell ausführlich auf Deine Handschrift trainiert werden.
Dafür ist aber die Einrichtung und Pflege von zahlreichen Trainingsdaten in Form von beschrifteten Wortbildern notwendig.
Das Projekt KI Sauklaue unterstützt Dich bei der Bereitstellung dieser Trainingsdaten. Dafür kannst Du Fotos zu Deiner Handschrift mit Deinem Smartphone fotografieren.
Dieses Fotos werden dann als Trainingsseite in KI Sauklaue erfasst, der korrekte Text Deiner Handschrift von Dir erfasst und mit Hilfe von zahlreichen Parametern, die einer Kalibrierung Deiner Handschrift entsprechen, der Text, die Zeilen und letztlich die einzelnen Worte aus dem Foto mit Deiner Handschrift extrahiert und separat abgespeichert.
Diesen Prozess kann unter dem Strukturelement „Trainingsseiten“ durchgeführt werden. Über den Button „Trainingsseiten“ gelangst Du in eine Übersicht Deiner Trainingsseiten (am Anfang ist dieser Bereich natürlich noch leer):
26. August 2025 17:26
Neue Trainingsseite / Bearbeiten einer Trainingsseite:
Die Anlage einer neuer Trainingsseite oder auch Bearbeitung einer bestehenden Trainingsseite untergliedert sich in die folgenden fünf Schritte:
-
Erfassung des Fotos und Erstellung des korrekten zeilengerechten Textes zum Foto
-
Eliminierung des Hintergrundes mit einer Leerseite
-
Textextrahierung
-
Zeilensegmentierung
-
Wortsegmentierung
Für jeden Bearbeitungsschritt, der immer in genau der gleichen Reihenfolge abgearbeitet werden muss, gibt zu jeder Trainingsseite ein eigenes Untermenü:
26. August 2025 17:28
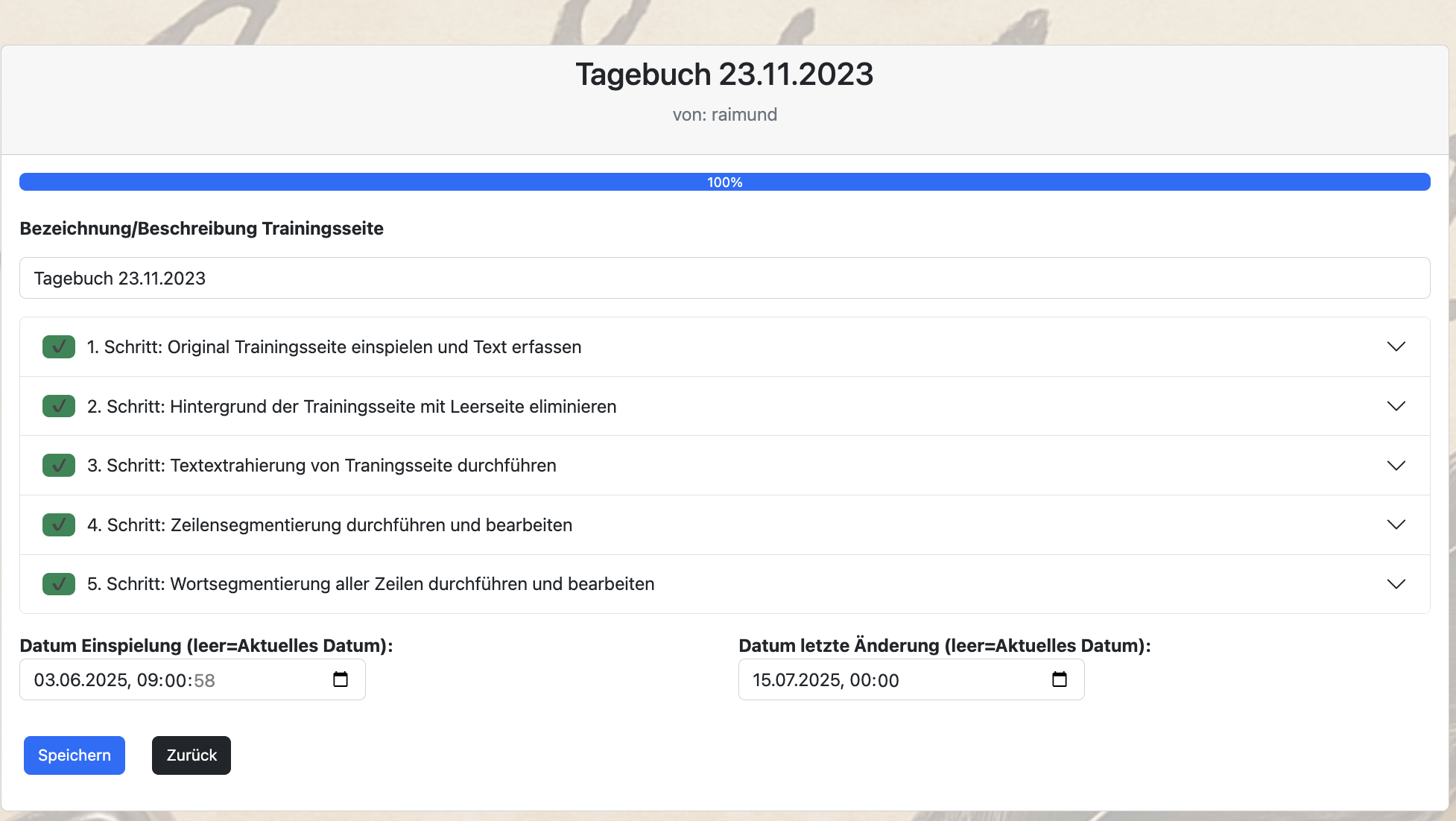
1. Schritt: Erfassung Foto und Erfassung Text
In der ersten Stufe wird ein Foto Deiner Handschrift gemacht, in die Trainingsseite eingespielt und dann der zugehörige Text zeilengerecht und am besten ohne Satzzeichen erfasst:
26. August 2025 17:29
2. Schritt: Eliminierung des Hintergrundes
Im zweiten Schritt wird der Hintergrund über eine einmalig definierte Leerseite (also dem Hintergrund) herausgerechnet. Genauer gesagt, werden dabei die Farben aus der Hintergrundseite vom Originalfoto angezogen. Dies ist eine recht verlässliche Methode. Achte nur darauf, dass die Stiftfarbe nicht zu exakt mit einer Farbe des Hintergrundes übereinstimmt. In diesen Fällen ist der Farbkorridor und die Anzahl der zu berücksichtigenden Farben bei der Leerseite sehr genau einzustellen

26. August 2025 17:30
3. Schritt: Textextrahierung
Im dritten Schritt wird der Text verstärkt und ggf. Unreinheiten, wie z.B. verbliebene Linien oder Kleckse, entfernt. Hier werden bereits zahlreiche individuelle Parameter zu Deiner Handschrift eingesetzt, die z.B. die Strichstärke und Deutlichkeit Deiner Handschrift berücksichtigt.

26. August 2025 17:31
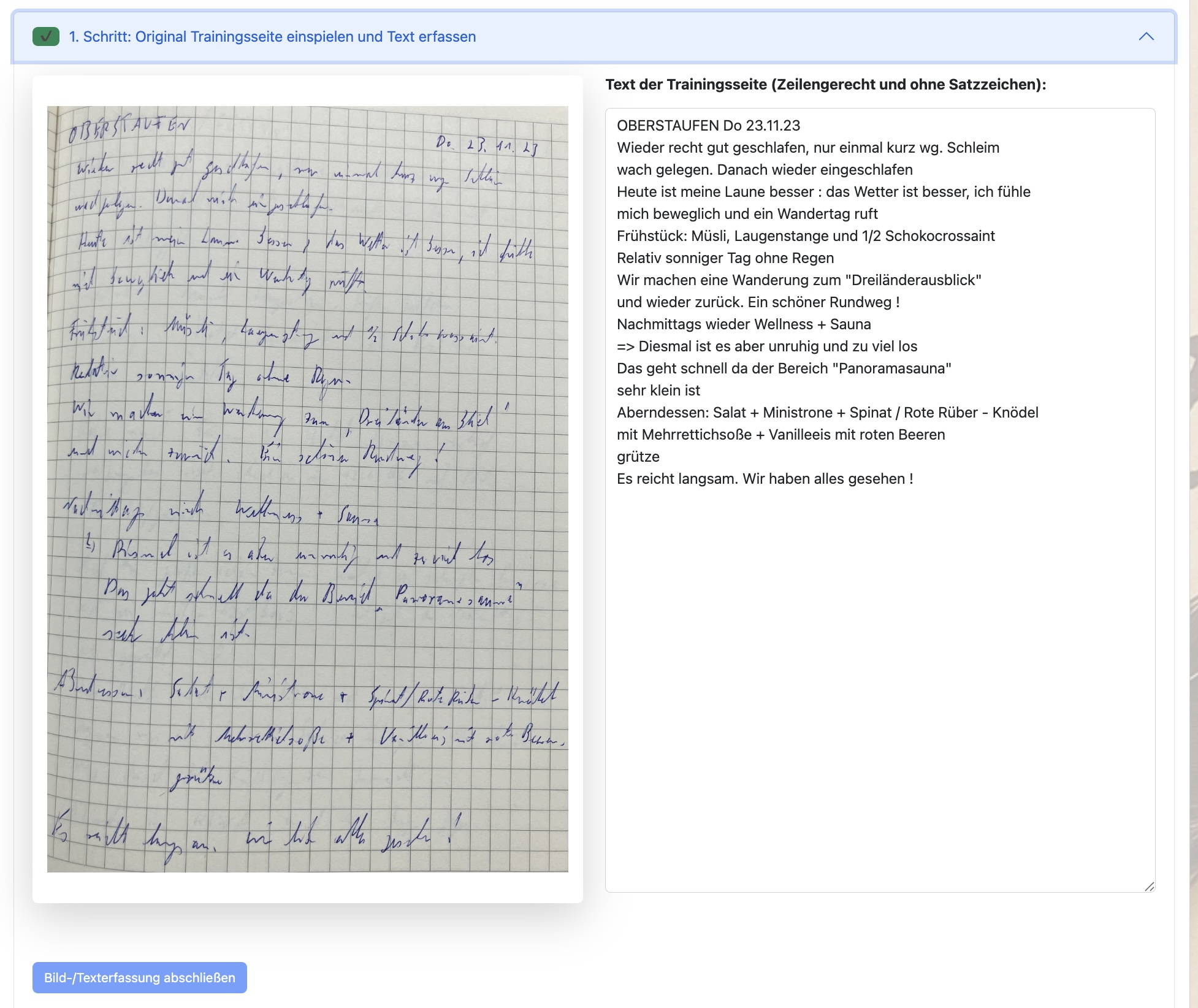
4. Schritt: Zeilensegmentierung
Im vierten Schritt wird der ermittelte Text nun in Textzeilen untergliedert. Dabei wird auf die ermittelten Parameter der individuellen Kalibrierung Deiner Schrift, die zum Modell oder User abgespeichert sind, zurückgegriffen.
26. August 2025 17:32
(Was meist gut funktioniert, aber manchmal (siehe Zeile 1) auch nicht ganz klappt)
26. August 2025 17:32
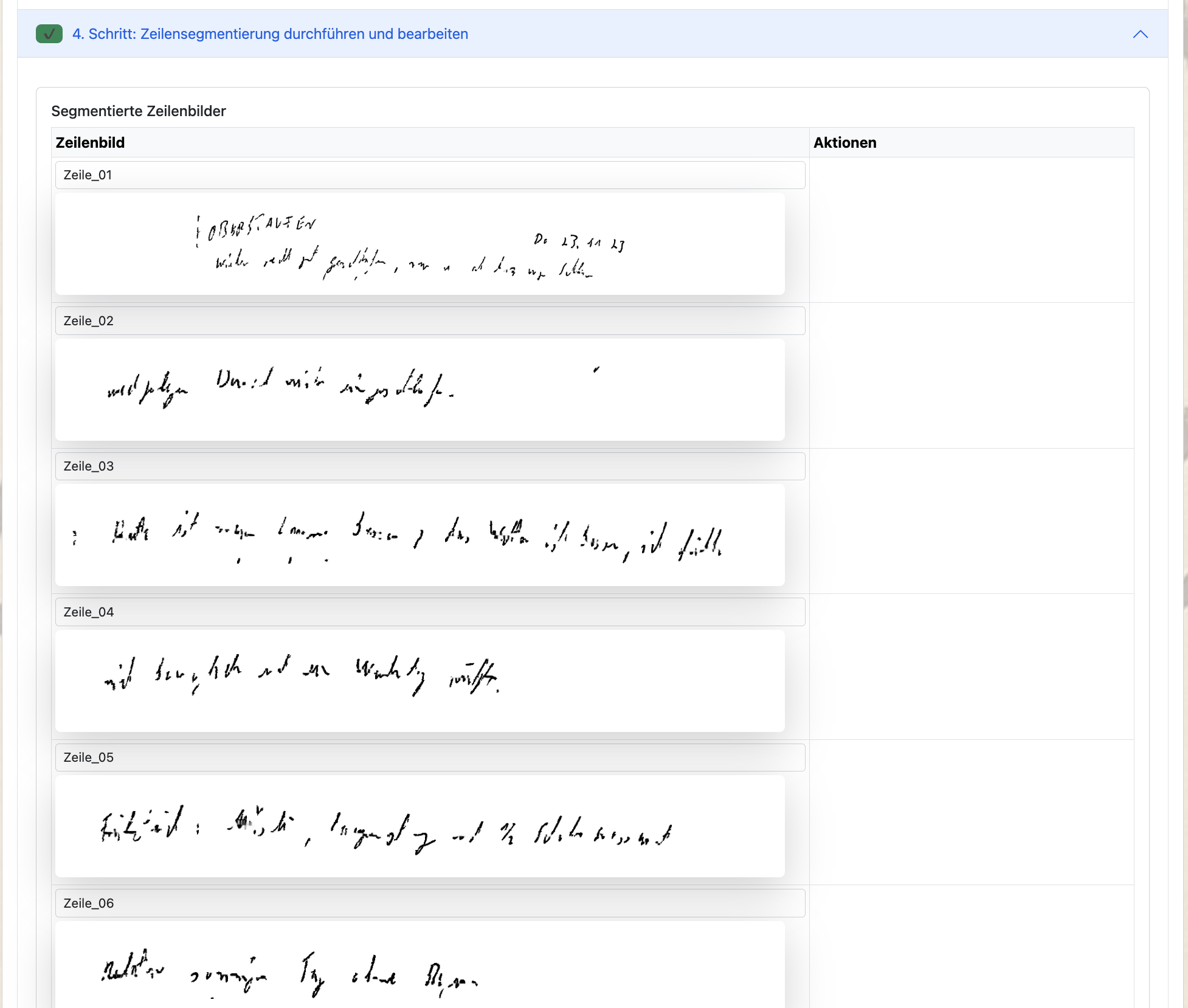
5. Schritt: Wortsegmentierung
Im fünften Schritt werden die Texte der Textzeilen automatisch in Wortbilder untergliedert. Auch hier wird auf die Parameter aus der Kalibrierung der Schrift zurückgegriffen. Zusätzlich werden zeilengerecht die einzelnen Worte aus der Texterfassung (Schritt 1) zugeordnet. Dies kann natürlich nochmal überarbeitet werden. Zusätzlich kann den Wortbildern über ein Wortlevel noch ein Grad der Komplexität mitgegeben werden (Level 0 = Standardschrift; Level 1 = kompliziertes Wort; Level 2 und höher = außergewöhnliche Schreibweise).
26. August 2025 17:34
Zu allen Parametern, die im Rahmen der Kalibrierung Deiner Handschrift zum Einsatz kommen können, siehe Kapitel Besonderheiten in der Kalibrierung Deiner Handschrift
26. August 2025 17:34
Die Leerseiten
Mit Hilfe der Leerseiten lassen sich der Hintergrund eines Fotos mit Deiner Handschrift herausrechnen. Die Leerseite ist quasi der Untergrund, auf dem Du Deinen Text geschrieben hast. Dies kann ein Blatt aus einem Notizbuch, einem Tagebuch oder einfach einem Block mit Linien- oder karierten Muster sein. Auch Ornamente oder andere Verzierungen auf dem Papier können das Erkennen Deiner Handschrift beeinflussen.
Um Deine Handschrift möglichst gut erkennen zu können, müssen alle anderen Bildinformationen herausgerechnet werden. Dazu muss wissen, woraus der Hintergrund besteht. Eben dies ist die Leerseite.
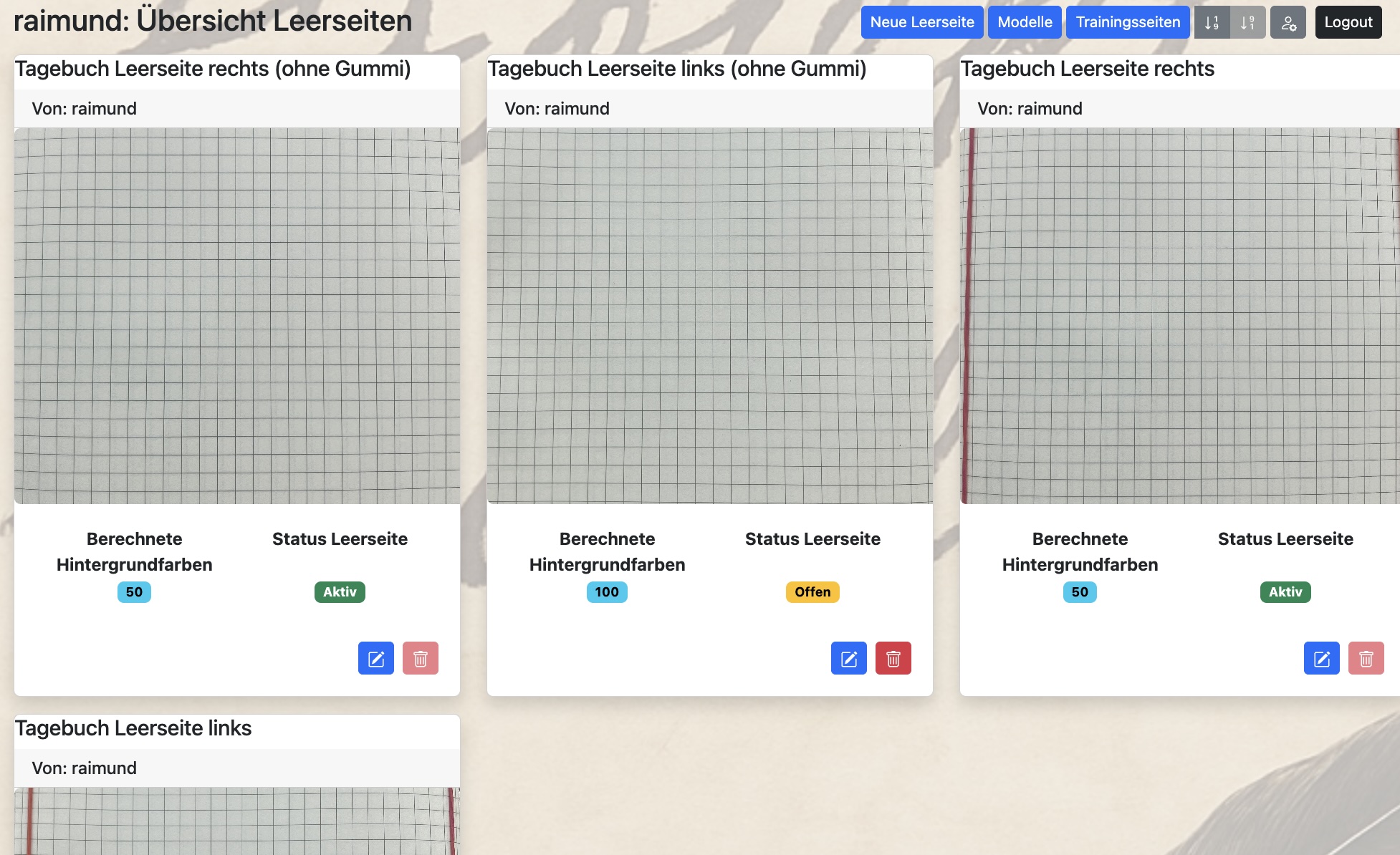
Über den Button „Leerseiten“ gelangst Du in die Übersicht Deiner Leerseiten, die am Anfang natürlich leer sein wird.
26. August 2025 17:35
Neue Leerseiten / Bearbeiten Leerseiten:
Über den Button „Neue Leerseite“ oder über den Button „Bearbeiten“ zu einer bestehenden Leerseite gelangst Du in Erfassung bzw. Bearbeitung einer Leerseite.
Dazu musst Du ein Foto von einer leeren Seite, auf der Du Deine handschriftlichen Texte erfasst, machen. Dieses Foto wird nun eingelesen. Dabei spielt es keine Rolle, ob die Leerseite in der Form genau in den Hintergrund Deiner Texte passt.
Es geht vielmehr um die Farben, die zu Deiner Hintergrundseite gehören. Der Hintergrund wird einfach dadurch herausgerechnet, in dem man die Farben der Leerseite berechnet und diese Farben einfach später aus dem Foto der Trainingsseite eliminiert.
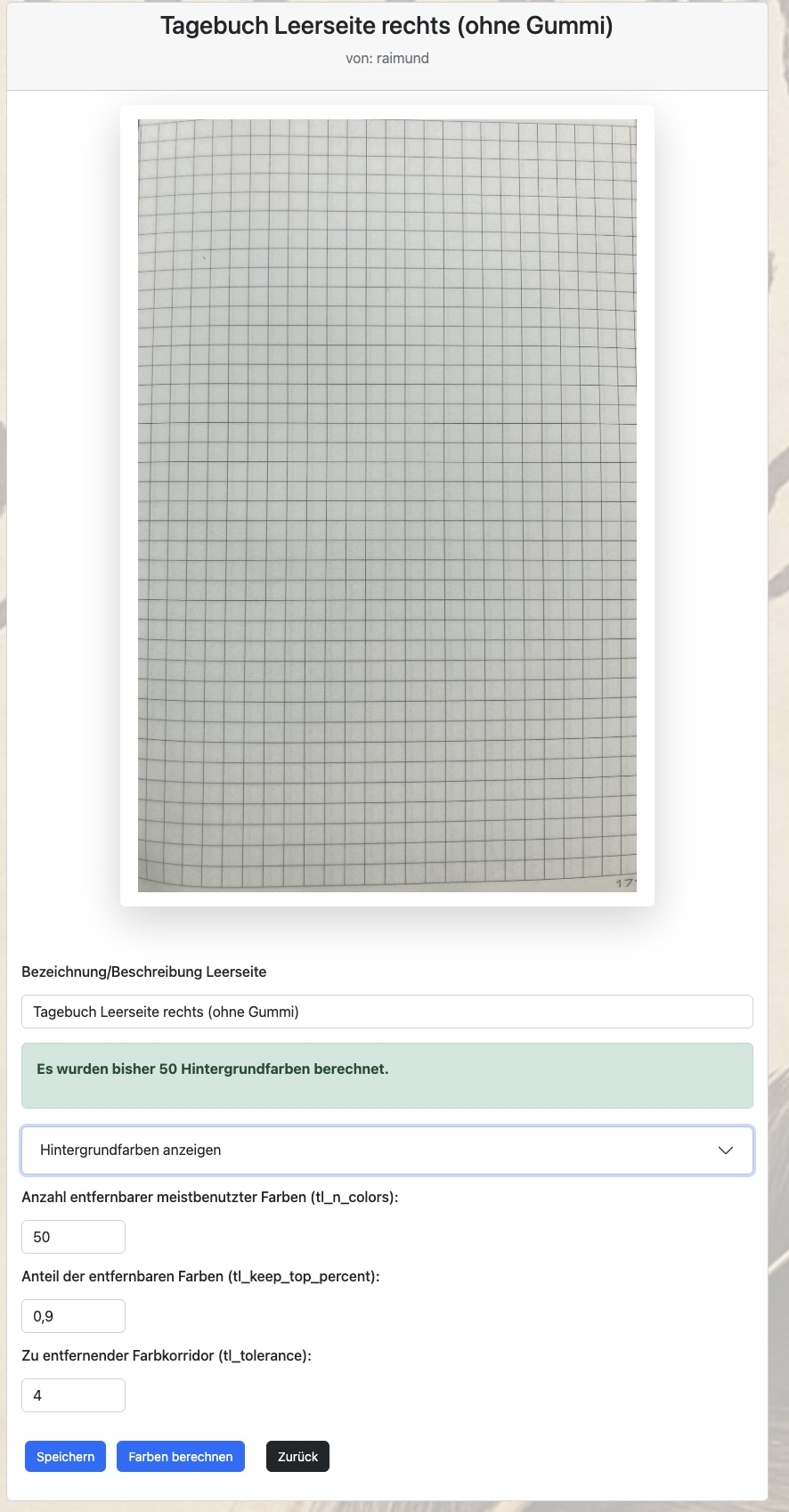
Aus diesem Grund wird nun in der Bearbeitung der Leerseite die Anzahl der wichtigsten Hintergrundfarben und ein Farbkorridor um diese Farben herum berechnet. Mit dem Farbkorridor sind die Variationen der berechneten Farben gemeint, die sich aus der Anzahl der RGB-Werte, um den Farbton herum ergeben. Wenn z.B. ein Farbton mit dem RGB-Werten 200-10-58 ermittelt wird, so meint der Farbkorridor 4 alle Farben im Bereich der RGB-Werte von 198-202; 8-12; 56-60.
Die Berechnung der wichtigsten Farben erfolgt über den Button „Farben berechnen“ und ist relativ zeitaufwendig. Um diesen Prozess bei Veränderungen nicht zu häufig durchführen zu müssen, kann man mit dem Parameter „Anteil der entfernbaren Farben“ als Prozentzahl, die relevanten Farben bei dem Prozess des Herausrechnens von Hintergrundfarben beeinflussen, ohne eine komplette neue Berechnung anstoßen zu müssen.
26. August 2025 17:37
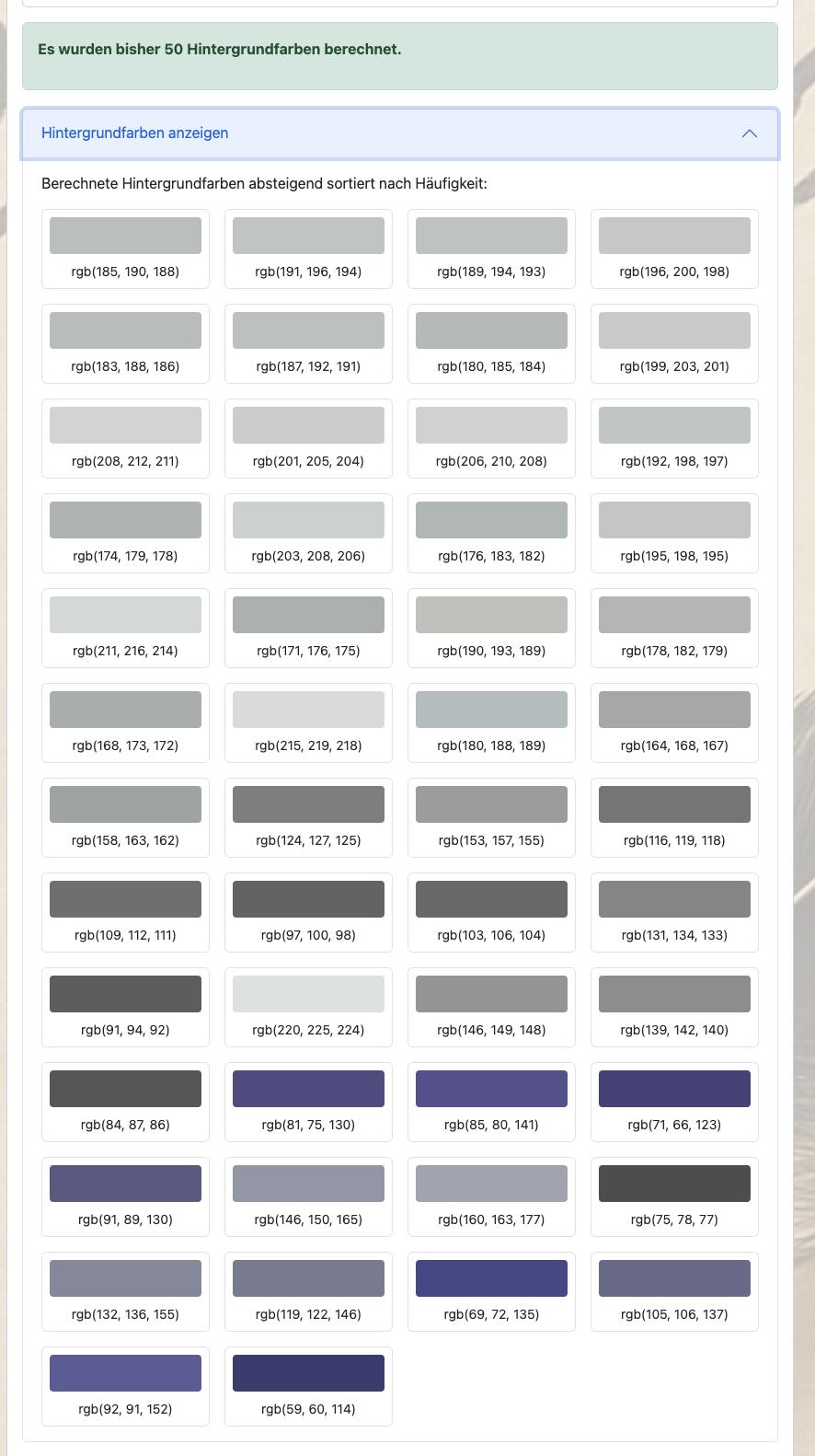
Im Untermenü „Hintergrundfarben anzeigen“ kannst Du dir die ermittelten Farben anzeigen lassen. Es empfiehlt sich zwischen 50 – 100 Farben berechnen zu lassen, wobei man mit 50 Farben mit einem Farbkorridor 4 schon sehr gute Ergebnisse erzielen kann.
Sollte die Stiftfarbe aber sehr ähnlich zu einer häufig genutzten Hintergrundfarbe sein, so sollte man mit einer höheren Anzahl Farben (80 – 100) aber einem kleinen Farbkorridor (z.B. 2) arbeiten, um eine feinere Abstimmung zu erhalten.
26. August 2025 19:35
Link zu KI Sauklaue - Einführung