KI Sauklaue - Kalibrierung
Raimund
26. August 2025 14:13
Besonderheiten in der Kalibrierung Deiner Handschrift
Was ist mit Kalibrierung der Handschrift gemeint?
Jede Handschrift ist sehr individuell in Bezug auf seine Form, Größe, Abstände usw.
Ein Modell im Projekt KI Sauklaue soll mit beliebigen Fotos Deiner Handschrift zurechtkommen und den Text daraus erkennen und in einzelne Wortbilder an das KI Modell (TrOCR) zur Texterkennung weitergeben.
Damit dies funktioniert muss das Modell auf Deine Handschrift in Bezug auf eine Reihe von Parametern kalibriert werden:

Raimund
26. August 2025 14:15
Darüber hinaus muss für das KI Modell der Text speziell verstärkt werden oder von einem Hintergrund gelöst werden.
Raimund
26. August 2025 14:15
Welche Verfahren und Parameter werden dabei angewendet?
Im Detail werden die folgenden Verfahren mit einer Reihe von Parametern, die zum Modell oder zum User (Profil) abgespeichert werden können, verwendet.
Ich entschuldige mich schon mal im Vorfeld, dass es jetzt relativ technisch wird.
Raimund
26. August 2025 14:16
Verfahren und Parameter zur Texterkennung und -extrahierung:
Gaussche Glättung
Die Gaussche Glättung ist ein fundamentales Verfahren zur Bildglättung, das Rauschen reduziert und feine Details weichzeichnet. Das Verfahren basiert auf einer mathematischen Funktion (Gauss-Funktion), die eine glockenförmige Verteilung beschreibt.
Bei der Gausschen Glättung wird jeder Bildpunkt durch einen gewichteten Durchschnitt seiner Nachbarpixel ersetzt. Die Gewichtung folgt dabei der Gauss-Verteilung: Pixel in der direkten Nachbarschaft haben mehr Einfluss als weiter entfernte Pixel. Dies erzeugt einen natürlichen, weichen Glättungseffekt ohne harte Kanten.
Der Parameter blur_kernel dabei definiert die Größe des Glättungsfilters und besteht aus zwei Werten: (Breite, Höhe) in Pixeln (z.B 3, 5, 7).
Raimund
26. August 2025 14:17
Schwarz-Weiß-Glättung:
Das bereits in Schwarz-Weiß-Töne umgewandelte Bild wird dabei eine reine schwarze Schrift und weißen Hintergrund umgewandelt. Damit werden nur leichte Striche hervorgehoben und andere Unfeinheiten herausgerechnet. Je höher der Parameter (150 – 225) desto mehr Grauwerte werden zu Weiß.
Raimund
26. August 2025 14:17
Linienentfernung mit Hough-Transformation und Inpainting:
Dieses Verfahren erkennt störende horizontale und/oder vertikale Linien im Bild und entfernt sie durch intelligente Rekonstruktion der darunterliegenden Bildinhalte.
Dabei werden folgende Funktionen genutzt:
-
Kantendetektion mit Canny-Algorithmus
-
Linienerkennung mit Hough-Transformation
-
Filterung nach Linienrichtung (horizontal/vertikal)
-
Maskenerstellung für erkannte Linien
-
Inpainting zur Rekonstruktion der maskierten Bereiche
Folgende Parameter können dabei eingestellt werden:
hough_thresh (Standard: 75 - 200)
Schwellwert für die Hough-Linienerkennung
Höhere Werte = nur sehr deutliche Linien werden erkannt
Niedrigere Werte = auch schwächere Linien werden gefunden
Bei Rauschen sollte der Wert höher gesetzt werden
min_line_len (Standard: 50 - 100)
Minimale Linienlänge in Pixeln
Linien kürzer als dieser Wert werden ignoriert
Verhindert Erkennung kleiner Störungen als "Linien"
max_line_gap (Standard: 10 - 20)
Maximale Lücke zwischen Liniensegmenten in Pixeln
Unterbrochene Linien werden als zusammenhängend betrachtet
Größere Werte verbinden mehr Segmente zu einer Linie
inpaint_radius (Standard: 2 - 3)
Radius für das Inpainting-Verfahren in Pixeln
Bestimmt, wie weit die Rekonstruktion in die Umgebung "blickt"
Größere Werte = glattere aber unschärfere Rekonstruktion
angle_thresh (Standard: 5 – 20 je nach Linienrichtung)
Winkeltoleranz in Grad für Linienrichtung
Bei "horizontal": Linien bis ±10° werden als horizontal betrachtet
Bei "vertical": Linien zwischen 80-100° werden als vertikal erkannt
apertureSize (Standard: 3, 5, 7)
Kernel-Größe für Canny-Kantendetektor (3, 5 oder 7)
Größere Werte = weniger empfindlich, glattere Kanten
thickness (Standard: 2 - 4)
Dicke der Linien in der Inpainting-Maske
Sollte mindestens so dick wie die zu entfernenden Linien sein
Zu dünne Werte lassen Linienreste übrig
Raimund
26. August 2025 14:19
Kontrastverstärkung mit CLAHE (Contrast Limited Adaptive Histogram Equalization)
CLAHE ist ein adaptives Histogramm-Ausgleichsverfahren, das den Kontrast lokal in kleinen Bildbereichen verbessert, anstatt das gesamte Bild gleichmäßig zu behandeln. Dies macht es besonders effektiv für Bilder mit ungleichmäßiger Beleuchtung oder schwachem Text.
Funktionsweise
-
Bildaufteilung: Das Bild wird in kleine rechteckige Kacheln (in Projekt KI Sauklaue 8x8 Pixel) unterteilt
-
Lokale Histogramm-Anpassung: Für jede Kachel wird das Histogramm separat ausgeglichen
-
Begrenzung: Übermäßige Kontrastverstärkung wird durch den clip_limit begrenzt
-
Interpolation: Übergänge zwischen Kacheln werden geglättet
Parameter clip_limit (Standard: 1.0 – 5.0)
Der clip_limit ist der wichtigste Parameter und begrenzt die maximale Kontrastverstärkung:
-
Niedrige Werte (1.0-2.0):
Sanfte, natürliche Kontrastverstärkung,
weniger Rauschen und Artefakte,
geeignet für normale Bildverbesserung
-
Mittlere Werte (2.0-4.0):
Deutliche Kontrastverbesserung,
guter Kompromiss zwischen Klarheit und Natürlichkeit,
Standard für schwachen Text
-
Hohe Werte (4.0+):
Sehr starke Kontrastverstärkung,
kann Rauschen verstärken und unnatürlich wirken,
nur bei sehr kontrastarmen Bildern empfehlenswert
Raimund
26. August 2025 14:23
Lückenschließen mit Dilation
Die Dilation ist eine morphologische Operation, die weiße (Vordergrund-)Bereiche in einem Binärbild erweitert und verdickt. Sie ist besonders nützlich, um kleine Lücken in Buchstaben oder Linien zu schließen und dünne Strukturen zu verstärken.
Funktionsweise
-
Strukturelement (Kernel) wird über jedes Pixel des Bildes bewegt
-
Wenn das Strukturelement mindestens ein weißes Pixel berührt, wird das zentrale Pixel auf weiß gesetzt
-
Dadurch werden weiße Bereiche in alle Richtungen erweitert
-
Kleine Lücken zwischen nahegelegenen weißen Bereichen werden "überbrückt"
Parameter-Erläuterungen:
dilation_kernel, Standard: (2, 2) bis (5,5)
Definiert Größe und Form des Strukturelements
-
(2, 2): Kleines elliptisches Element für sanfte Erweiterung
-
(3, 3): Mittlere Erweiterung, schließt kleine Lücken
-
(5, 5): Stärkere Erweiterung, kann aber Details verlieren
Auswirkungen der Kernel-Größe:
-
Kleinere Kernel: Präzise, schließen nur sehr kleine Lücken
-
Größere Kernel: Aggressiver, können benachbarte Buchstaben verbinden
-
Elliptische Form: Natürlichere Erweiterung als rechteckige Kernel
dilation_iterations, Standard: 1 - 4
Anzahl der Wiederholungen der Dilation-Operation
-
iterations=1: Einmalige, kontrollierte Erweiterung
-
iterations=2: Stärkere Erweiterung, schließt größere Lücken
-
iterations≥3: Sehr starke Erweiterung, Risiko von Buchstabenverbindungen
Raimund
26. August 2025 14:26
Entfernung kleiner Flecken (Noise Removal)
Dieses Verfahren funktioniert wie ein intelligenter digitaler Radiergummi, der gezielt kleine störende schwarze Flecken und Rauschpunkte aus binären Bildern entfernt, während wichtige Textstrukturen erhalten bleiben.
Funktionsweise
-
Bildinvertierung: Schwarze Flecken werden zu weißen Objekten (einfachere Analyse)
-
Connected Components Analysis: Jeder zusammenhängende schwarze Bereich wird als separates "Objekt" identifiziert und vermessen
-
Größenfilterung: Objekte werden nach ihrer Pixelanzahl (Fläche) bewertet
-
Selektive Entfernung: Nur Objekte unterhalb der Größenschwelle werden "radiert"
-
Rekonstruktion: Kleine Flecken werden durch weiße Pixel ersetzt
Parameter max_fleckgroesse (Standard: 0 - 60)
Dieser Parameter definiert die kritische Fleckengröße in Pixeln und ist der wichtigste Steuerparameter:
Kleine Werte (10-30 Pixel):
-
Entfernt nur winzige Störungen und Rauschpunkte
-
Sehr konservativ, behält fast alle Textstrukturen
-
Geeignet für saubere Scans mit geringem Rauschen
Mittlere Werte (30-60 Pixel):
-
Standard-Einstellung für normale Bildreinigung
-
Entfernt typische Flecken und kleine Artefakte
-
Guter Kompromiss zwischen Reinigung und Texterhaltung
Raimund
26. August 2025 14:28
Verfahren und Parameter zur Zeilensegmentierung:
Zeilensegmentierung mit Horizontalprojektion
Die Zeilensegmentierung ist ein Verfahren zur automatischen Erkennung von Textzeilen in einem Dokument. Es nutzt die charakteristische Eigenschaft, dass zwischen Textzeilen meist deutliche weiße Zwischenräume (Zeilenzwischenräume) existieren.
Funktionsweise
-
Bildinvertierung: Schwarzer Text wird zu weiß, weißer Hintergrund zu schwarz
-
Horizontalprojektion: Summierung aller weißen Pixel pro Bildzeile → ergibt ein 1D-Projektionsprofil
-
Glättung: Gaussian-Filter reduziert Rauschen im Projektionsprofil
-
Invertierung des Profils: Täler (Zeilenzwischenräume) werden zu Peaks
-
Peak-Detektion: Automatische Erkennung der Zeilentrenner als Maxima
Projektion verstehen
-
Hohe Werte im Projektionsprofil = viel Text in dieser Zeile
-
Niedrige Werte = wenig/kein Text = Zeilenzwischenraum
-
Nach Invertierung werden Zeilenzwischenräume zu deutlichen Peaks
Parameter-Erläuterungen
distance (Mindestabstand zwischen Peaks; Standard 20-80 Pixel (abhängig der Zeilenhöhe)
Verhindert Erkennung mehrerer Peaks innerhalb einer Textzeile
-
Zu klein: Jede kleine Lücke wird als Zeilentrenner erkannt
-
Zu groß: Eng stehende Zeilen werden nicht getrennt
-
Faustregel: Etwa 60-80% der erwarteten Zeilenhöhe
prominence (Mindest-Ausgeprägtheit der Peaks, Standard 10.000 – 100.000)
Definiert, wie deutlich ein Peak vom Umgebungsprofil abstechen muss
-
Niedrige Werte (10.000- 15.000): Erkennt auch schwache Zeilentrenner
-
Mittlere Werte (20.000- 100.000): Standard für normale Dokumente
-
Hohe Werte (150+): Nur sehr deutliche Zeilenzwischenräume
-
Zu niedrig: Erkennt Störungen als Zeilen
-
Zu hoch: Übersieht echte Zeilentrenner bei engem Zeilenabstand
Praktisch lassen sich die Peaks zur Unterteilung einer Textseite in einzelne Zeilen wie folgt darstellen:
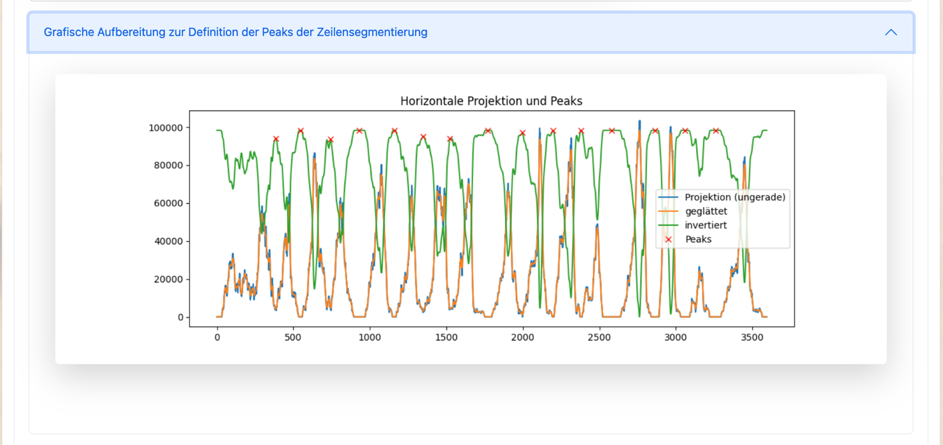
Raimund
26. August 2025 14:34
Verfahren und Parameter zur Wortsegmentierung:
Wortsegmentierung aus Textzeilen
Die Wortsegmentierung unterteilt eine bereits erkannte Textzeile in einzelne Wörter. Das Verfahren nutzt morphologische Operationen, um Buchstaben innerhalb von Wörtern zu verbinden und anschließend die entstehenden zusammenhängenden Bereiche als separate Wörter zu extrahieren.
Funktionsweise
-
Binarisierung: Konvertierung zu Schwarz-Weiß-Bild (invertiert: Text = weiß)
-
Horizontale Dilation: Erweitert Textbereiche horizontal → verbindet Buchstaben zu Wortblöcken
-
Konturerkennung: Findet zusammenhängende weiße Bereiche (= potentielle Wörter)
-
Geometrische Filterung: Aussortierung nach Größe und Position
-
Wortextraktion: Ausschneiden der gefilterten Bereiche als einzelne Wortbilder
Schlüsselkonzept: Horizontale Dilation
Die horizontale Dilation mit rechteckigem Kernel ist der Kern des Verfahrens:
-
Buchstaben innerhalb eines Wortes werden horizontal "überbrückt"
-
Größere Abstände zwischen Wörtern bleiben als Trennung erhalten
-
Entstehende Blöcke entsprechen kompletten Wörtern
Parameter-Erläuterungen
word_kernel (Standard: 40 - 80)
Horizontale Breite des Dilation-Kernels in Pixeln
Bestimmt, welche Buchstabenabstände als "ein Wort" behandelt werden
-
Kleinere Werte (40-50): Konservativ, trennt auch eng stehende Wörter
-
Standard-Werte (60-70): Optimal für normale Schriftarten
-
Größere Werte (80+): Verbindet auch weit gespreizte Buchstaben
Praktische Auswirkung:
-
Zu klein: Einzelne Buchstaben werden als separate "Wörter" erkannt
-
Zu groß: Mehrere Wörter verschmelzen zu einem Block
-
Anpassung an Schriftart: Breitere Schriften brauchen höhere Werte
min_word_width (Standard: 40-120)
Minimale Breite eines gültigen Wortes in Pixeln
Filtert kleine Störungen und Satzzeichen heraus
-
Niedrigere Werte (40-80): Behält auch kurze Wörter und Satzzeichen
-
Standard-Werte (100-120): Ignoriert einzelne Buchstaben und Punkte
-
Höhere Werte (150+): Nur lange Wörter werden erkannt
Zielkonflikt bei min_word_width:
-
Vorteil: Filtert Rauschen und I-Punkte effektiv
-
Nachteil: Kurze Wörter ("I", "a") und Satzzeichen gehen verloren
Zusatzparameter corridor (0.2)
Definiert einen vertikalen Korridor um die Zeilenmitte (±20% der Zeilenhöhe), um oberhalb/unterhalb liegende Störungen herauszufiltern.
Raimund
26. August 2025 14:38
Größenanpassung mittels Scretching oder Padding:
Zur Aufbereitung der Wortbilder für das TrOCR-Systems gehört die Anpassung der Wortbilder auf eine fixe Größe:
Verfahren: Stretching vs. Padding
Beide Verfahren passen die extrahierten Wortbilder auf eine einheitliche Größe von 384×384 Pixeln an, um sie für maschinelles Lernen (OCR/Texterkennung) vorzubereiten. Die Verfahren unterscheiden sich grundlegend in ihrer Herangehensweise.
Raimund
26. August 2025 14:38
Stretching (Strecken/Dehnen)
Das Wortbild wird direkt auf 384×384 Pixel skaliert, unabhängig vom ursprünglichen Seitenverhältnis.
Charakteristika:
-
Verzerrung: Das Seitenverhältnis wird nicht beibehalten
-
Füllung: Das gesamte 384×384-Feld wird ausgefüllt
-
Interpolation: LANCZOS4 sorgt für hochwertige Skalierung
Vorteile:
-
Maximale Pixelausnutzung des Zielformats
-
Einheitliche Bildgröße ohne leere Bereiche
-
Einfache, schnelle Implementierung
Nachteile:
-
Verzerrung der Proportionen: Schmale Wörter werden künstlich breit, breite Wörter gestaucht
-
Erkennbarkeit: Lange Wörter werden extrem komprimiert und schwer lesbar
-
Unnatürliches Aussehen: Buchstaben verlieren ihre ursprünglichen Proportionen
Raimund
26. August 2025 14:39
Padding (Auffüllen mit Rand)
Das Wortbild wird proportional skaliert und anschließend mit weißem/schwarzem Rand auf 384×384 Pixel aufgefüllt.
Charakteristika
-
Proportionen bleiben erhalten: Seitenverhältnis wird nicht verändert
-
Zentrierung: Das skalierte Wort wird in der Mitte platziert
-
Randauffüllung: Leere Bereiche werden mit Hintergrundfarbe gefüllt
Vorteile:
-
Natürliche Proportionen: Buchstaben behalten ihre ursprüngliche Form
-
Bessere Erkennbarkeit: Besonders bei langen Wörtern deutlich lesbar
-
Realitätsnähe: Entspricht eher dem natürlichen Erscheinungsbild
Nachteile:
-
Ungenutzte Bildbereiche (Padding-Bereiche)
-
Komplexere Implementierung
-
Verschiedene Wortgrößen im finalen Bild
Raimund
26. August 2025 19:34
Link zu KI Sauklaue - Einführung