KI Sauklaue - Vorhersage
Raimund
26. August 2025 14:44
Kapitel: Funktionen und Techniken zur Vorhersage und Post-Processing
Was ist mit Vorhersage (Predict) und Post-Processing (Nachbearbeitung) gemeint?
Im Stufenmodell des Projekte KI Sauklaue werden ausführlich die drei grundsätzlichen Schritte im Verhalten in der Handschriftenerkennung des Projekte KI Sauklaue erläutert:
Die Handschriftenerkennung erfolgt dabei in den folgenden drei Stufen:
-
Die Vorverarbeitung mit der Aufbereitung der handschriftlichen Texte
-
Die Vorhersage durch das mit Deiner Handschrift trainierte TrOCR-Modell
-
Die Nachbearbeitung mit einem Large Language Modell (LLM), um semantische Zusammenhänge und Themenspezifische Kontexte zu erkennen und zu berücksichtigen
Für mehr Details siehe dazu Kapitel „Stufen der Handschrifterkennung im Projekt Sauklaue“
In diesem Abschnitt beschreiben wir nun Deine Möglichkeiten die Vorhersage (Stufe 2) und die Nachbearbeitung (Stufe 3) durchzuführen bzw. über geeignete Parameter zu beeinflussen.
Raimund
26. August 2025 14:45
Wie kann ich nun eigentlich handschriftliche Texte erkennen lassen?
Das Erkennen des handschriftlichen Textes kann im Projekt KI Sauklaue über drei verschiedene Methoden erfolgen:
1. Funktion Predict zu einem Modell oder Modellstand:
Dies ist die einfache standard online Funktion zur Erkennung Deines handschriftlichen Textes. Minimale Daten und schnelle Ergebnisse stehen hier im Vordergrund.
2. Funktion Predict Detail zu einem Modell oder Modellstand:
Mit Predict Detail gelangst Du eine umfangreichere Oberfläche zur Erkennung Deiner handschriftlichen Texte. Alle handschriftlichen Texte, die von einem Modell des Projektes KI Sauklaue erkannt und analysiert wurden, werden dauerhaft gespeichert.
In dieser Oberfläche kannst Du diese Vorhersagen im Detail betrachten, korrigieren oder die Vorhersage des TrOCR-Moduls oder das Post-Prozessing des LLM erneut anstoßen.
Auch Funktionen zur Übernahme der Vorhersagen als neue Trainingsdaten oder die Einrichtung von Batch-Jobs, um im Hintergrund eine ganze Reihe von handschriftlichen Texten analysieren zu lassen, stehen in dieser Oberfläche zur Verfügung.
3. Externer Zugriff über eine eigene API-Schnittstelle:
Mit einer eigenen API-Schnittstelle erlaubt das Projekt KI Sauklaue auch den externen Zugriff auf ein einzelnes Modell oder Modellstand und ermöglicht die Entgegennahme eines Fotos zu einer Handschrift, analysiert die Daten und gibt den ermittelten Text in einem Standardformat wieder zurück.
Damit kann beispielsweise auf Deinem MacBook oder Deinem IPhone aus der Foto-App direkt ein Foto übergeben und die Handschrift analysiert werden.
Raimund
26. August 2025 15:00
Wie kann ich am einfachsten im KI Projekt Sauklaue einen Text erkennen lassen?
Das funktioniert mit einfachsten mit der Funktion „Predict“.
Diese Funktion kannst Du zu jedem aktiven Modellstand eines Modells oder direkt zu einem Modell, dass mindestens einen aktiven Modellstand besitzt, aufrufen.
Dem Modell wird dabei immer automatisch der aktuellste aktive Modellstand für das Erkennen Deiner Handschrift zugeordnet.
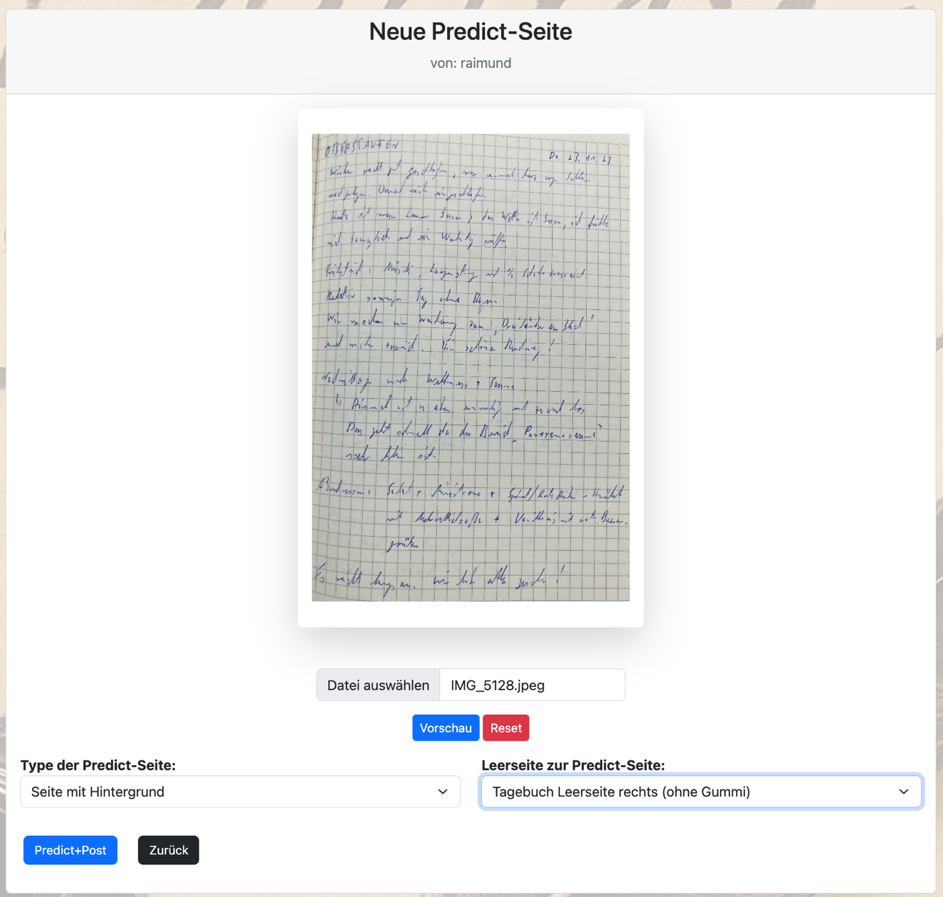
Bei Predict musst Du nur minimale Angaben machen:
-
das Foto mit Deiner Handschrift,
-
einem Typ der zu erkennenden Handschrift
(Seite mit Hintergrund,
Seite mit Textextrahierung,
Seite mit reinem Text,
Zeile,
Wort)
-
Nur beim Typ „Seite mit Hintergrund“ muss dann noch im Projekt KI Sauklaue vorhandene Leerseite (als Vorlage für den Hintergrund) ausgewählt werden.
Raimund
26. August 2025 15:04
Über den Button „Predict+Post“ wird das Foto und die anderen Angaben entgegengenommen und Deine Handschrift sowohl durch das TrOCR als auch durch die Nachbearbeitung mit einem LLM-Modell erkannt.
Das Ergebnis kannst Du dann als neue Predict-Seite in „Predict Detail“ betrachten.
Raimund
26. August 2025 15:05
Wie kann ich mehr Informationen/Funktionen zu meinen erkannten Handschriften bekommen?
Deutlich mehr Möglichkeiten, um mit Deinen handschriftlichen Texten zu arbeiten, finden sich auf der Oberfläche von „Predict Detail“.
Auch diese Funktion kannst Du zu jedem aktiven Modellstand eines Modells oder direkt zu einem Modell, dass mindestens einen aktiven Modellstand besitzt, aufrufen.
Dem Modell wird dabei immer automatisch der aktuellste aktive Modellstand für das Erkennen Deiner Handschrift zugeordnet.
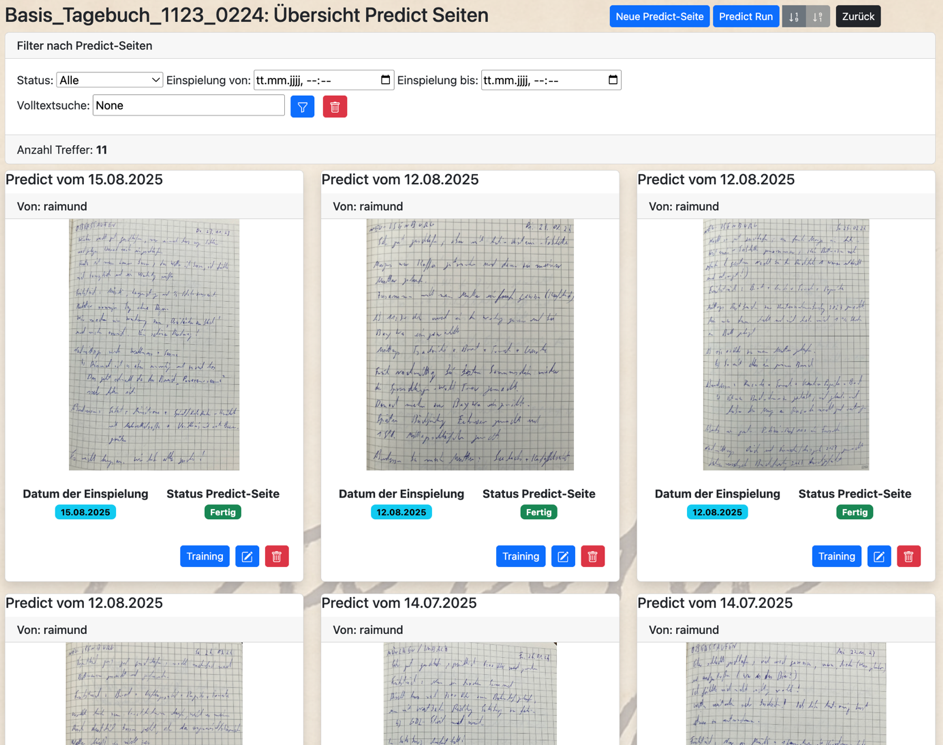
In Predict Detail werden Dir alle gespeicherten Vorhersagen zu einem Modellstand aufgelistet. Es gilt für alle Vorhersagen, ob aus Predict, Predict detail oder dem externen Zugriff über die API-Schnittelle: Alle Vorhersagen werden dauerhaft gespeichert und können auf dieser Oberfläche analysiert, korrigiert, nachbearbeitet oder auch wieder gelöscht werden:
Raimund
26. August 2025 15:06
Über die Funktion „Neue Predict Seite“ können auch auf dieser Oberfläche neue Fotos zu analysierenden Handschriften erfasst und gespeichert werden.
Mit der Funktion „Predict Run“ ist es auch möglich, zunächst nur erfasste Fotos, in einem Batch Job im Hintergrund zusammen analysieren zu lassen. Bei vielen Texten kann dies hilfreich sein, da diese Form der Analyse nicht die Oberfläche blockiert, sondern separat in aller Ruhe die Fotos der Handschriften bearbeitet.
Über die Funktion „Bearbeiten“ kommst Du in die Details zu jeder Vorhersage:
Raimund
26. August 2025 15:08
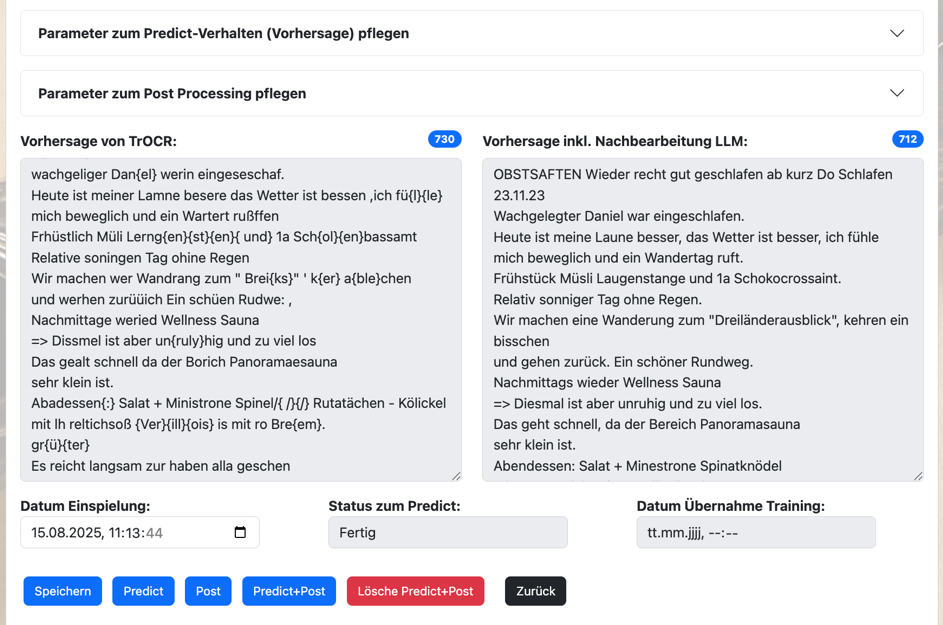
Hier werden Dir die erkannten Texte in zwei Stufen im Detail vorgestellt.
Der Text „Vorhersage von TrOCR“ enthält den reinen Text, der aus dem trainierten TrOCR-Modell gekommen ist. Texte in geschweiften Klammern stellen dabei sehr unsichere Annahmen des Modells dar.
Der Text „Vorhersage inkl. Nachbearbeitung LLM“ stellt dann den finalen Text nach einer Nachbearbeitung durch ein LLM, wie z.B. ChatGPT, dar. Hier fließen dann semantische Zusammenhänge aus dem Satzkontext und auch die Begriffe einer Schlagwortliste in die Nachbearbeitung ein.
Über die Funktionen „Predict“, „Post“, „Predict+Post“ und „Lösche Predict+Post“ kannst die Vorhersagen und Nachbearbeitungen erneut durchlaufen lassen oder löschen.
Raimund
26. August 2025 15:09
Wie funktioniert die API-Schnittstelle zur Predict-Funktion?
Hierzu gibt es ein eigenes Kapitel Die API-Schnittstelle zum Projekt KI Sauklaue
Raimund
26. August 2025 15:09
Wie kann ich das Predict-Verhalten beeinflussen, welche Parameter gibt es dabei?
Die Predict-Funktion ist quasi das Herzstück Deines TrOCR-Systems. Es nimmt Bilder von Wörtern entgegen und "liest" diese automatisch aus - ähnlich wie ein Mensch Text von einem Foto abliest. Dabei nutzt sie künstliche Intelligenz (TrOCR-Modell), um aus Pixeln wieder lesbaren Text zu machen.
Dabei kannst Du das Verhalten der Predict-Funktion über eine Reihe von Parametern beeinflussen (Fortgeschrittene Techniken):
max_new_tokens - "Wie lang darf der erkannte Text werden?"
-
Begrenzt die maximale Anzahl der Wörter/Zeichen, die erkannt werden
-
Empfehlung: 20-50 für normale Wörter, mehr für längere Texte
num_beams - "Wie gründlich soll gesucht werden?"
-
Das Modell probiert mehrere Möglichkeiten parallel aus
-
Analogie: Wie ein Schachspieler, der mehrere Züge im Voraus denkt
-
Empfehlung: 3-5 (guter Kompromiss zwischen Qualität und Geschwindigkeit)
early_stopping - "Soll gestoppt werden, wenn ein Wort komplett ist?"
-
True: Stoppt sofort, wenn ein vollständiges Wort erkannt wurde → Schneller
-
False: Sucht weiter nach besseren Alternativen → Genauer, aber langsamer
-
Empfehlung: True für die meisten Anwendungen
no_repeat_ngram_size - "Verhindere sinnlose Wiederholungen"
-
Verhindert, dass sich Wortteile unsinnig wiederholen
-
Praktisches Beispiel:
-
Ohne: "Hallo-lo-lo-lo" oder "der der der"
-
Mit (Wert 3): "Hallo" (normal)
-
Empfehlung: 2-4
repetition_penalty - "Bestrafe Wiederholungen"
-
Macht wiederholte Buchstaben/Wörter unwahrscheinlicher
-
Werte: 1.0 = keine Bestrafung, 1.5 = moderate Bestrafung, 2.0= hohe Bestrafung
-
Empfehlung: 1.0-2.0
length_penalty - "Bevorzuge kurze oder lange Texte?"
-
< 1.0: Bevorzugt kürzere Erkennungen
-
1.0: Neutral
-
1.0: Bevorzugt längere Erkennungen
-
Empfehlung: 1.0 – 1.5 für ausgewogene Ergebnisse
Die Spezialfunktion: Unsicherheits-Erkennung
show_uncertain und threshold - "Zeige mir, wo das Modell unsicher ist"
-
Das KI-Modell kann nicht nur Text erkennen, sondern auch sagen, wie sicher es sich bei jedem Buchstaben ist.
-
Praktisches Beispiel:
-
Eingabebild: Unleserliches "Hallo"
-
Normale Ausgabe: "Hallo"
-
Mit Unsicherheits-Markierung: "H{a}llo"
-
Das bedeutet: Das Modell ist sich beim "a" unsicher
threshold (Schwellwert):
-
0.9: Sehr streng - markiert viele Stellen als unsicher
-
0.7: Moderat - markiert nur wirklich problematische Stellen
-
0.5: Locker - markiert nur extreme Unsicherheiten
Wann ist das nützlich?
-
Qualitätskontrolle: Du siehst sofort problematische Stellen
-
Vertrauen: Wissen, welchen Erkennungen Sie vertrauen können
-
Nachbearbeitung: Können gezielt unsichere Stellen manuell korrigieren
-
Zusammenspiel mit LLM: Insbesondere im Prompt für das LLM in der Nachbearbeitung kann darauf hingewiesen werden, dass Tokens in geschweiften Klammern ein unsicheres Ergebnis darstellen und wahrscheinlicher überarbeitet werden müssen.
Raimund
26. August 2025 15:15
Wie kann ich die Nachbearbeitung (Post Processing) durch ein LLM beeinflussen?
Der Prozess der Nachbearbeitung durch ein LLM-Modell nimmt das Ergebnis aus der Predict-Funktion des TrOCR-Modells und überarbeitet die gefundenen Begriffe in Bezug auf einen semantischen Satzzusammenhang und stellt den gesamten Text über eine Schlagwortliste in einen Themenkontext.
Auch hierbei gibt es eine Reihe von Parametern, mit dem der Prozess der Nachbearbeitung beeinflusst werden kann.
Modell zum Post Processing:
Definiert das Large Language Modell, dass im Rahmen des Post Processing genutzt wird. Aktuell kann nur ChatGPT.com ausgewählt werden.
Neben den großen externen LLM-Modellen wäre aber auch die Anwendung eines lokalen LLM, wie etwa BERT denkbar.
Wird kein Modell angegeben, findet auch keine Nachbearbeitung statt.
System Prompt:
Beschreibt für das Large Language Modell seine aktuelle Aufgabe als OCR-Korrekturassistent für deutschsprachige handschriftliche Texterkennungen.
Je ausführlicher der System Prompt die Aufgabe des LLM beschreibt, umso genauer werden die Ergebnisse in der Nachbearbeitung sein.
Wichtig sind dabei Hinweise, wie z.B. „Du gibst nur den bereinigten Text zurück – keine Kommentare oder Erklärungen.“ Um zu erreichen, dass wirklich nur der bereinigte Text übergeben wird und keine weiteren Erläuterungen des Modells.
User Prompt:
Konkretere Beschreibung in der aktuellen Überarbeitung und Korrektur des OCR-Textes. Beschreibe zum Beispiel typische Fehler in der OCR-Erkennung und stelle eine möglichst genaue Aufgabenstellung.
Wichtig ist das am Ende der Aufgabenstellung folgender Punkt steht: „Verwende exakt diese Schreibweise für bekannte Begriffe (wenn aus dem Kontext erkennbar):“. Daran anschließend werden automatisch alle Schlüsselbegriffe aus der Schlagwortliste des Modells – mit Komma getrennt – angefügt.
Raimund
26. August 2025 19:35
Link zu KI Sauklaue - Einführung