KI Sauklaue - Stufenmodell
Raimund
26. August 2025 12:08
Stufen der Handschrifterkennung im Projekt Sauklaue
Wie funktioniert eigentlich die Handschriftenerkennung im Projekt KI Sauklaue?
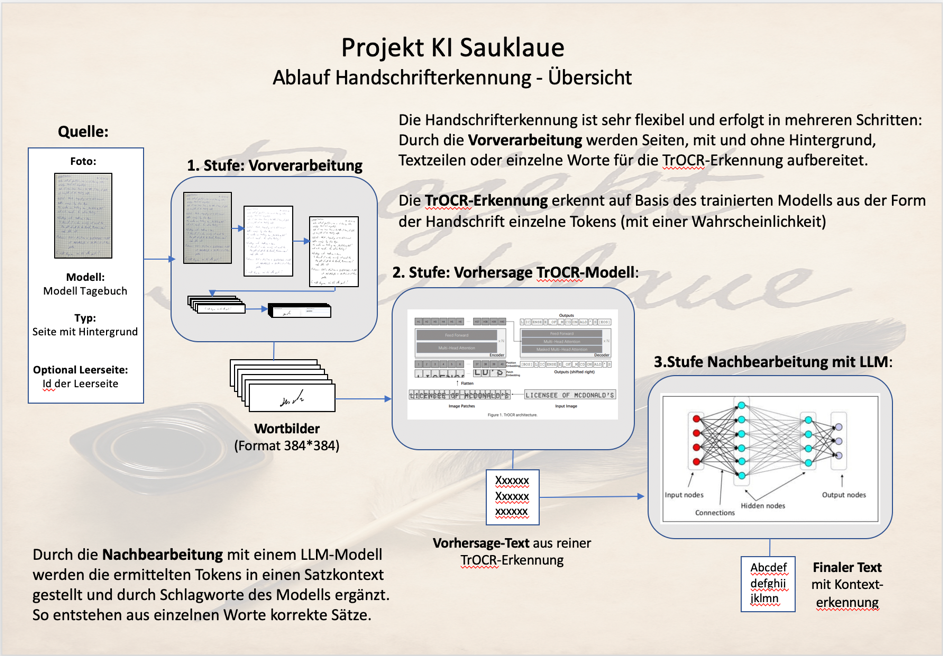
Aus der Überlegung zu den Besonderheiten und Eigenarten einer unleserlichen Handschriftenerkennung wird deutlich, dass es sich im Projekt KI Sauklaue um mehr handelt als um eine reine OCR-Erkennung mit einem trainierten Transfermodell.
Vielmehr funktioniert die Handschriftenerkennung in drei Stufen:
-
Die Vorverarbeitung mit der Aufbereitung der handschriftlichen Texte
-
Die Vorhersage durch das mit Deiner Handschrift trainierte TrOCR-Modell
-
Die Nachbearbeitung mit einem Large Language Modell (LLM), um semantische Zusammenhänge und Themenspezifische Kontexte zu erkennen und zu berücksichtigen
Raimund
26. August 2025 12:10
Die Vorverarbeitung:
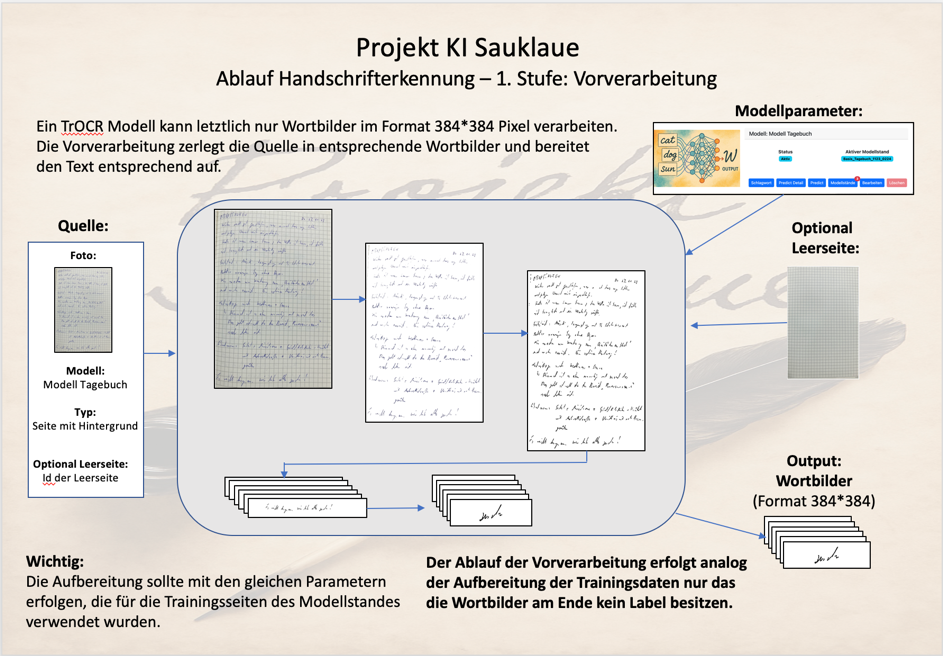
Die Vorverarbeitung bereitet den handschriftlichen Text so auf, dass es von dem TrOCR-Modell überhaupt verarbeitet werden kann.
Dabei durchläuft das Foto mit dem handschriftlichen Text maximal 4 Detailstufen, je nachdem um welche Art von Text es sich handelt.
In der maximalen Ausprägung, also z.B. einer Seite aus einem Tagebuch, sind dies die folgenden Stufen:
-
Entfernung des Hintergrundes, um den reinen handschriftlichen Text in Schwarz-Weiß zu erhalten. Dazu kann das Foto eine Leerseite mit angegeben werden, auf der der handschriftliche Text geschrieben wurde.
Durch Abziehen der Farben dieser Leerseiten kann zuverlässig eine reine Textseite berechnet werden.
-
In einem weiteren Schritt wird der so gewonnene Text auf dem Schwarz-Weiß-Bild weiter hervorgehoben und kleine Lücken geschlossen. Weiterhin werden verbliebene Artefakte, z.B. horizontale und (im Karoformat) vertikale Linien oder aber Flecken oder andere Fehler aus der Aufnahme versucht zu entfernen.
-
Im dritten Schritt wird auf Basis der Parameter aus der Kalibrierung der Handschrift das gesamte Textbild in einzelne Textzeilen untergliedert.
-
Im letzten Schritt der Vorverarbeitung werden schließlich die Textzeilen wiederum in einzelne Wortbilder untergliedert und in einem Format von 384x384 Pixel-Bildern aufbereitet.
Raimund
26. August 2025 12:13
Damit durchläuft die Vorverarbeitung die gleichen Schritte wie die Trainingsfotos, die letztlich ebenfalls in viele Wortbilder untergliedert werden und als Training für das TrOCR-Modell dienen. Der einzige Unterschied besteht darin, dass das Trainingsmaterial zusätzlich ein Label mit dem korrekten Begriff enthält.
Für Details zu den einzelnen Parametern und dem technischen Vorgehen siehe daher auch Kapitel „Trainieren eines TrOCR-Systems mit Deiner Handschrift“.
Raimund
26. August 2025 12:14
Die Vorhersage im TrOCR-Modell:
In der zweiten Stufe werden nun die einzelnen Wortbilder (384x384 Pixel-Format) jedes für sich in dem TrOCR-Modell durchlaufen:
Raimund
26. August 2025 12:16
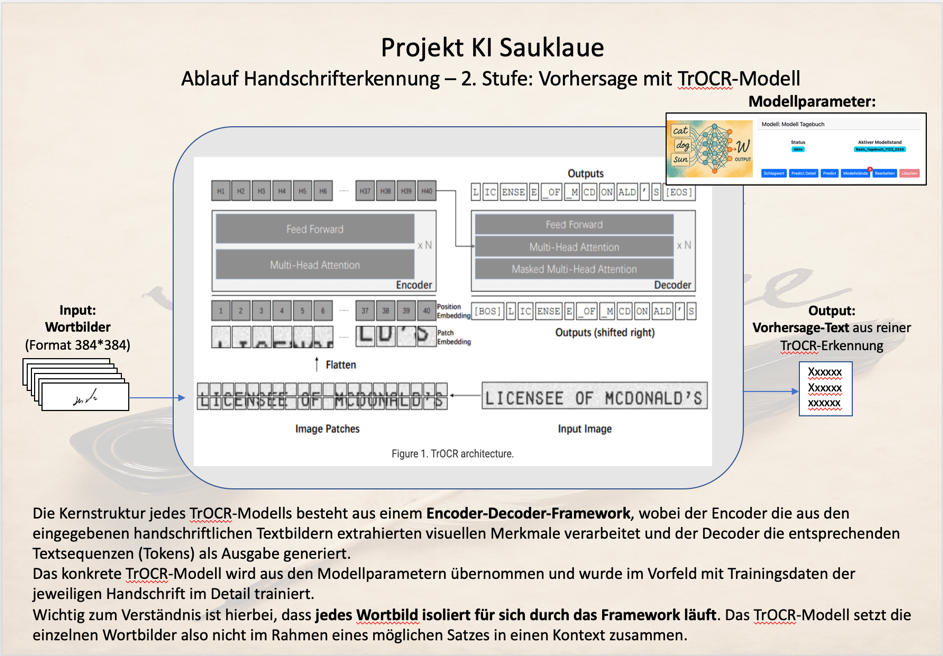
Grundlage ist immer ein TrOCR-Modell von Microsoft, dass mit handschriftlichen Texten Deiner Handschrift verfeinert wurde. Es ist ein System zur Texterkennung, das auf Transformer-Architekturen basiert und einen methodischen Ansatz zur Verarbeitung von Textbildern verfolgt.
Grundarchitektur von TrOCR
Dieses TrOCR besteht aus zwei spezialisierten Komponenten:
Der Vision Encoder: Analysiert und verarbeitet das Eingabebild
Der Text Decoder: Konvertiert die Bildanalyse in Textausgabe
Der Vision Encoder - Bildanalyse und -verarbeitung
Schritt 1: Systematische Bildaufteilung
Das System unterteilt jedes 384x384 Pixel großes Wortbild in ein regelmäßiges Raster von kleinen Bildausschnitten. Konkret entstehen 576 quadratische Bereiche von jeweils 16x16 Pixeln (24 mal 24 Bereiche). Diese Aufteilung ermöglicht eine strukturierte Analyse des gesamten Bildes, bei der kein Bereich übersehen wird.
Die Aufteilung erfolgt systematisch von links nach rechts und von oben nach unten, sodass jeder Bildausschnitt eine eindeutige Position im Gesamtbild hat.
Schritt 2: Extraktion von Bildeigenschaften
Jeder der 576 Bildausschnitte wird einzeln analysiert und in eine numerische Darstellung umgewandelt. Das System extrahiert dabei Informationen über Helligkeit, Kontraste, Kanten und andere visuelle Eigenschaften. Diese Analyse erfolgt durch mathematische Operationen, die aus den ursprünglichen Pixelwerten aussagekräftige Merkmalsvektoren erstellen.
Jeder Bildausschnitt wird dadurch zu einem Datensatz mit mehreren hundert Eigenschaften, die seine visuellen Charakteristika beschreiben.
Schritt 3: Positionsinformation hinzufügen
Da die Reihenfolge und Position der Bildausschnitte für die Texterkennung entscheidend sind, ergänzt das System jeden Merkmalvektor um Positionsinformationen. Jeder Bildausschnitt erhält dadurch zusätzlich zu seinen visuellen Eigenschaften auch Informationen über seine Position im ursprünglichen Bild.
Schritt 4: Kontextuelle Analyse
Das System analysiert nun alle Bildausschnitte gemeinsam und identifiziert Zusammenhänge zwischen benachbarten und entfernten Bereichen. Durch Aufmerksamkeitsmechanismen werden Verbindungen zwischen verschiedenen Bildregionen hergestellt, um zusammenhängende Strukturen wie Buchstabenteile oder ganze Zeichen zu erkennen.
Diese Analyse erfolgt in mehreren aufeinanderfolgenden Verarbeitungsschichten, wobei jede Schicht komplexere Muster und Strukturen identifiziert als die vorherige.
Der Text Decoder - Textgenerierung
Schritt 1: Integration der Bildinformationen
Der Text Decoder erhält die vom Vision Encoder erstellten Bildrepräsentationen und nutzt diese als Grundlage für die Textgenerierung. Das System kann dabei auf die Informationen aller Bildausschnitte zugreifen und diese bei jeder Entscheidung berücksichtigen.
Schritt 2: Sequenzielle Textgenerierung
Der Decoder arbeitet sequenziell und generiert das erkannte Wort Zeichen für Zeichen von links nach rechts. Bei jedem Schritt nutzt das System sowohl die Bildinformationen als auch die bereits generierten Zeichen, um das nächste Zeichen vorherzusagen.
Die Vorhersage basiert auf statistischen Mustern, die das System während des Trainings aus großen Datenmengen gelernt hat.
Schritt 3: Kontextuelle Textverarbeitung
Parallel zur Bildanalyse verarbeitet der Decoder auch die sprachlichen Zusammenhänge der bereits generierten Wortsequenz. Dies ermöglicht es dem System, sprachlich plausible Vorhersagen zu treffen und dabei sowohl visuelle als auch linguistische Informationen zu berücksichtigen. Diese beschränken sich aber immer auf die Angaben des einen Wortbildes.
Durch die Verarbeitung aller Wortbilder durch die Encoder-Decoder-Einheiten entstehen einzelne Worte, deren Tokens mit einer gewissen Wahrscheinlichkeit versehen sind. Bei Tokens, deren Unsicherheit eine gewisse Schwelle überschreitet, kann der das Token in geschweiften Klammern angegeben werden, um dem nachfolgenden Prozess diese Unsicherheit mitzuteilen. Alternativ können Tokens mit einer gewissen Unsicherheit auch gelöscht werden.
Raimund
26. August 2025 12:19
Die Nachbearbeitung durch Large Language Models (LLM):
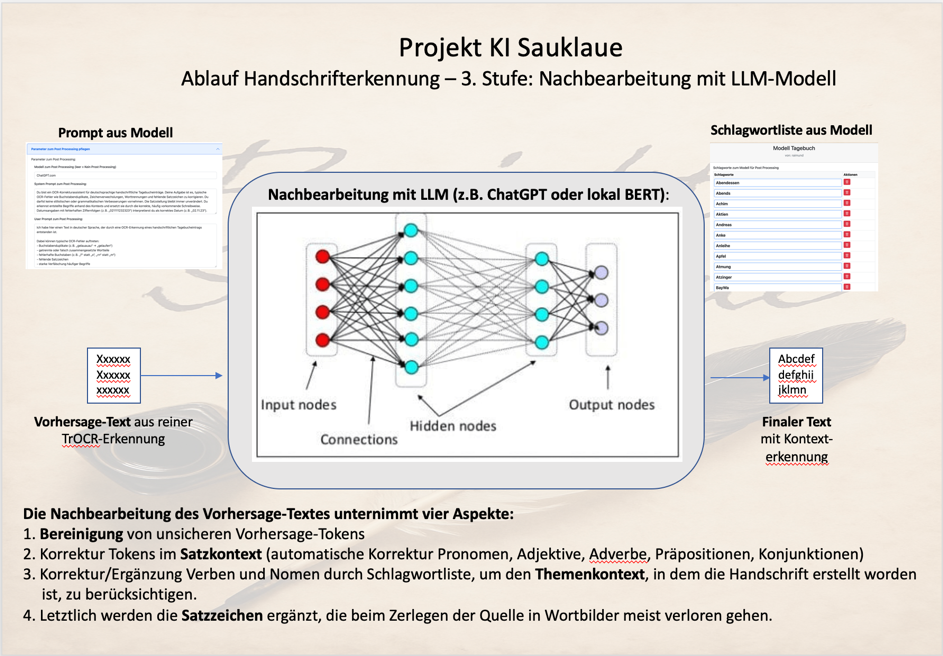
Der ermittelte Text des TrOCR-Modells durchläuft nun eine zusätzliche Verarbeitungsschicht durch ein Large Language Model (LLM). Dies kann entweder ein externes LLM, wie etwa ChatGPT oder Claude über einen API-Zugriff oder aber ein internen LLM, wie etwa BERT sein.
Diese Nachbearbeitung kompensiert die inhärenten Beschränkungen der wortweisen Verarbeitung und verbessert die Gesamtqualität der Texterkennung durch kontextuelle Analyse und thematische Einordnung.
Raimund
26. August 2025 12:20
Grundlegende Herausforderung der wortweisen Verarbeitung
Isolierte Wortverarbeitung: Da TrOCR einzelne 384x384 Pixel Wortbilder verarbeitet, entstehen isolierte Textfragmente ohne Satzkontext. Das System kann nicht erkennen, wie Wörter grammatikalisch oder inhaltlich zusammenhängen, da ihm die übergeordnete Satzstruktur fehlt.
Akkumulation von Erkennungsfehlern: Fehler bei der Einzelworterkennung können sich über längere Textpassagen hinweg akkumulieren, ohne dass eine Korrekturmöglichkeit durch Kontext besteht.
Der LLM-Nachbearbeitungsprozess
Schritt 1: Eingabe der Wortsequenz
Das LLM erhält eine Sequenz von einzelnen Wörtern oder Tokens, die das TrOCR-Modell aus den aufeinanderfolgenden Wortbildern extrahiert hat. Diese Sequenz repräsentiert die zeitliche oder räumliche Reihenfolge der ursprünglichen Wortbilder, enthält jedoch keine Satzzeichen, Groß-/Kleinschreibung oder andere strukturelle Elemente.
Schritt 2: Kontextuelle Rekonstruktion
Das LLM analysiert die Wortsequenz und identifiziert wahrscheinliche Satzgrenzen, grammatikalische Strukturen und semantische Zusammenhänge. Durch sein Training auf großen Textkorpora kann das System typische Wortfolgen erkennen und daraus plausible Satzstrukturen ableiten.
Das System rekonstruiert dabei Interpunktion, Groß- und Kleinschreibung sowie andere orthographische Konventionen basierend auf den erkannten grammatikalischen Strukturen.
Schritt 3: Integration der Schlagwortliste
Parallel zur kontextuellen Analyse erhält das LLM eine themenspezifische Schlagwortliste, die als Referenzrahmen für die Textkorrektur dient. Diese Liste definiert den erwarteten Wortschatz und die thematischen Schwerpunkte des zu verarbeitenden Textes.
Schritt 4: Fehleridentifikation und -korrektur
Das LLM identifiziert Wörter, die nicht zum erwarteten Kontext passen oder orthographische Anomalien aufweisen. Dabei nutzt es mehrere Korrekturstrategien:
-
Ähnlichkeitsbasierte Korrektur: Wörter mit geringer Wahrscheinlichkeit werden mit ähnlichen Begriffen aus der Schlagwortliste verglichen und bei hoher Ähnlichkeit ersetzt
-
Kontextuelle Plausibilitätsprüfung: Wörter werden auf ihre Passung in den identifizierten Satzkontext geprüft
-
Thematische Kohärenz: Die Gesamtkonsistenz des Textes wird unter Berücksichtigung der vorgegebenen Thematik bewertet
Verarbeitungsmechanismen des LLM
Probabilistische Textanalyse: Das LLM bewertet jede mögliche Textinterpretation anhand statistischer Wahrscheinlichkeiten, die aus seinem Training abgeleitet sind. Sätze und Wortfolgen werden nach ihrer Plausibilität in der deutschen Sprache und im gegebenen Themenkontext bewertet.
Mehrstufige Hypothesengenerierung: Für unklare oder mehrdeutige Worterkennungen generiert das System mehrere alternative Interpretationen und wählt die wahrscheinlichste basierend auf Kontext und Schlagwortliste aus.
Konsistenzprüfung: Das System überprüft die Konsistenz von Begriffen, Schreibweisen und thematischen Bezügen über den gesamten Text hinweg und harmonisiert Abweichungen.
Diese integrierte Herangehensweise kompensiert die Limitierungen der wortweisen Bildverarbeitung aus der zweiten Stufe und erzeugt zusammenhängende, thematisch konsistente Texte mit verbesserter Erkennungsqualität.
Raimund
26. August 2025 19:34
Link zu KI Sauklaue - Einführung