KI Sauklaue - Unleserliche Handschriften
Raimund
26. August 2025 11:34
Unleserliche Handschriften – Eigenarten, Besonderheiten
Was können aktuelle OCR-Systeme?
Moderne OCR-Systeme (Optical Character Recognition) haben in den letzten Jahren erhebliche Fortschritte gemacht und können heute eine beeindruckende Bandbreite an Texterkennungsaufgaben bewältigen. Ihre Leistungsfähigkeit variiert jedoch stark je nach Art des zu erkennenden Textes.
Maschinelle Texte: Nahezu perfekte Erkennung
Bei maschinell erstellten Texten erreichen heutige OCR-Systeme außerordentlich hohe Genauigkeitsraten von oft über 98%. Diese Systeme können problemlos verschiedene Schriftarten, Größen und Layouts verarbeiten. Selbst bei leicht verzerrten oder qualitativ minderwertigen Scans liefern sie zuverlässige Ergebnisse. Moderne OCR-Programme nutzen dabei Deep-Learning-Algorithmen und künstliche neuronale Netze, die aus Millionen von Textbeispielen gelernt haben.
Besonders effektiv sind diese Systeme bei standardisierten Dokumenten wie Rechnungen, Formularen oder gedruckten Büchern. Sie können dabei nicht nur den Text extrahieren, sondern auch die Dokumentstruktur erkennen, Tabellen verstehen und sogar mehrsprachige Dokumente verarbeiten.
Handschriftliche Texte: Deutliche Qualitätsunterschiede
Die Erkennung handschriftlicher Texte stellt OCR-Systeme vor weitaus größere Herausforderungen. Hier zeigen sich erhebliche Qualitätsunterschiede je nach Lesbarkeit der Handschrift:
Gut lesbare Handschriften können moderne OCR-Systeme durchaus erfolgreich verarbeiten, insbesondere wenn die Schrift klar strukturiert, gleichmäßig und in Druckbuchstaben verfasst ist. Spezialisierte Systeme für Handschrifterkennung (HTR - Handwritten Text Recognition) erreichen hier Genauigkeitsraten von 80-95%.
Durchschnittliche Handschriften mit individuellen Eigenarten, ungleichmäßiger Schreibweise oder Schreibschrift werden bereits deutlich schlechter erkannt. Die Fehlerrate steigt merklich an, und oft sind manuelle Nachkorrekturen erforderlich.
Die Grenze: Unleserliche Handschriften
Unleserliche oder sehr schlecht lesbare Handschriften stellen nach wie vor eine nahezu unüberwindbare Hürde für aktuelle OCR-Systeme dar. Wenn selbst Menschen Schwierigkeiten haben, eine Handschrift zu entziffern, versagen auch die fortschrittlichsten Erkennungssysteme. Faktoren wie extrem unregelmäßige Buchstabenformen, starke Verschleifungen, unleserliche Verbindungen zwischen Buchstaben oder stark verwischte Tinte führen dazu, dass die Erkennungsrate praktisch gegen Null geht.
Zusammenfassung:

Raimund
26. August 2025 11:38
Welche handschriftlichen Texte können OCR-Systeme erkennen?
Ein in der Literatur weit verbreiteter Benchmark für handschriftliche Texte, die benutzt wurden, um die Qualität von OCR-Systemen zu messen, ist der CVL-Dataset der TU-Wien.
Der CVL-Dataset der TU Wien ist eine öffentliche Datenbank, die 2013 am Computer Vision Lab (CVL) entwickelt wurde und aus 7 verschiedenen handschriftlichen Texten (1 deutschem und 6 englischen Text) mit insgesamt 311 verschiedenen Schreibern besteht. 27 Schreiber verfassten alle 7 Texte, während 283 Schreiber jeweils 5 Texte schrieben.
Der Dataset wurde speziell für drei Hauptanwendungsbereiche konzipiert: Writer Retrieval (Schreiber-Suche), Writer Identification (Schreiber-Identifikation) und Word Spotting (Wort-Erkennung). Für jeden Text stehen RGB-Farbbilder in 300 dpi-Auflösung zur Verfügung, die sowohl den handgeschriebenen als auch den gedruckten Referenztext enthalten, sowie zugeschnittene Versionen mit nur dem handschriftlichen Text.
Der CVL-Dataset wurde 2013 auf der International Conference on Document Analysis and Recognition (ICDAR) vorgestellt und hat sich seitdem als wichtiger Standard in der Handschrifterkennungs-Community etabliert. Er ermöglicht es Forschern, ihre Algorithmen unter kontrollierten Bedingungen zu testen und Leistungsvergleiche mit anderen Systemen durchzuführen. Der Dataset steht unter der Creative Commons Attribution-NonCommercial 3.0 Lizenz zur Verfügung.
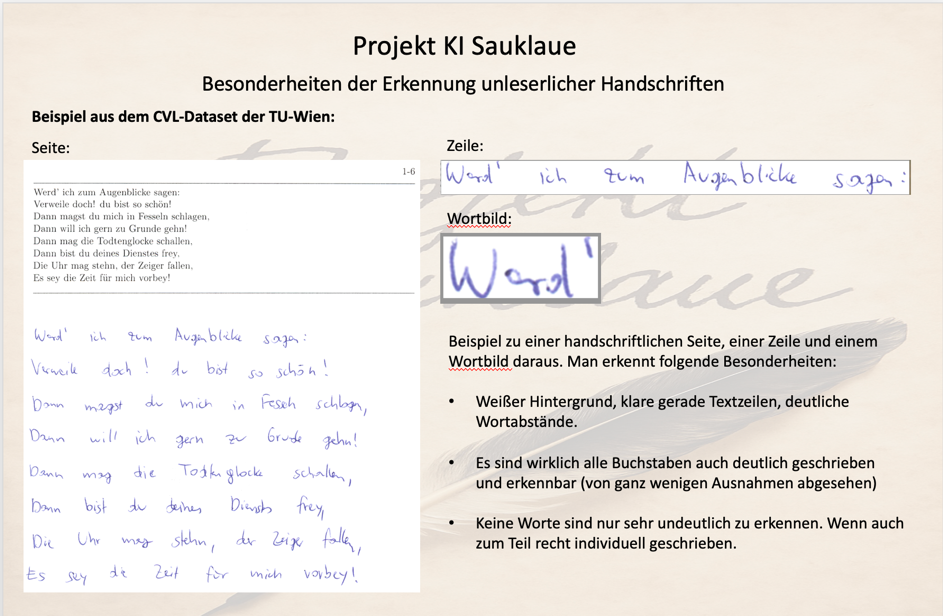
Um den Dataset besser zu verstehen, schauen wir uns ein Beispiel an:
Raimund
26. August 2025 11:40
Es fallen sofort folgende Merkmale auf:
-
Die Handschrift ist auf einem klaren weißen Hintergrund geschrieben
-
Die Textzeilen sind schnurgerade (es ist anzunehmen, dass beim Verfassen eine Schablone mit Textlinien als Unterlage verwendet wurde)
-
Alle Buchstaben fein säuberlich, von ganz wenigen Ausnahmen abgesehen, aufgeschrieben und zu erkennen
-
Keins der Worte ist undeutlich geschrieben oder durch einen Scan vielleicht nur undeutlich aufgenommen worden.
Diese sehr saubere Abbildung von handschriftlichen Texten, auch in unterschiedlicher Schreibweise, können heutige OCR-System mit einer Qualität von ca. 95% recht gut erkennen.
Allerdings ist diese Form der handschriftlichen Texte (außerhalb des Schönschreibunterrichtes in der Grundschule) im Alltag unrealistisch und damit scheitern in der Praxis auch aktuelle OCR-Systeme weitgehend bei dieser Aufgabe.
Vor welchen Herausforderungen stand das Projekt KI Sauklaue konkret?
Das Ziel des Projektes KI Sauklaue besteht darin, für einen Anwender eine individuelle Handschriftenerkennung zu ermöglichen, die alltagstauglich ist.
Kalibrierung und Hintergrund:
Schauen wir uns also ein praktisches Beispiel an - Mein Tagebuch:

Raimund
26. August 2025 11:48
Es fällt sofort auf, dass der Text einfach mit dem IPhone - mit Stärken und Schwächen in der Aufnahmequalität – aufgenommen wurde und natürlich nicht auf einem reinen weißen Hintergrund, sondern mit dem Untergrund des Tagebuchs inkl. Wellen in der Seitendarstellung.
Weiterhin ist der Text nicht exakt regelmäßig oder auch die Zeilen sind nicht genau gerade und unterschiedlich ausführlich beschrieben.
Ein weiteres Augenmerk fällt sofort auf die spezielle Handschrift in Form, Größe, Breite, Zeilenabstand, Wortlücken usw. auf.
Eine wesentliche Herausforderung besteht bei KI Sauklaue also zunächst einmal darin, die individuelle Handschrift zu erkennen und für ein individuelles TrOCR-Modell zu beschreiben.
Dazu findet eine Art „Kalibrierung“ der jeweiligen Handschrift statt, in der die wichtigsten Eigenarten der Handschrift (ohne konkret auf die Schrift einzugehen) an Hand von verschiedenen Parametern ermittelt wird:

Raimund
26. August 2025 11:52
Ein weiterer Schritt besteht darin, bei der Texterkennung dem eingescannten Foto zusätzlich ein Foto mit einer Leerseite z.B. des Tagebuchs – quasi als Hintergrundbild – mitzugeben.
Aus den Farben der Leerseite kann dann der Hintergrund zuverlässig herausgerechnet gerechnet werden, um einen reinen Text auf weißem Hintergrund zu erhalten.
Zusätzliche Techniken, wie Linien entfernen, kleinste Textlücken schließen und Texthervorhebungen, schaffen damit die Grundlage für die Texterkennung.
Auf Basis der Kalibrierungsparameter der Handschrift können dann Textzeilen und Wortbilder berechnet werden.
Undeutliche Wortendungen, verschwommene Worte, Abkürzungen:
Doch damit nicht genug. Wird z.B. beim CVL-Dataset jedes Wort, ja jeder Buchstabe, fein säuberlich aufgeschrieben, so ist dies in der Praxis einer unleserlichen Handschrift häufig nicht der Fall:

Raimund
26. August 2025 11:55
Diese undeutlichen Worte betreffen häufig Wortendungen oder auch Pronomen, Adjektive, Adverbe, Präpositionen oder Konjunktionen. Hier kommt das Modell eines TrOCR per se an seine Grenzen, da es immer nur einzelne Wortbilder interpretiert.
Wenn nun aber das korrekte Wort nicht aus der geschriebenen Form der Handschrift selbst, sondern nur im Kontext z.B. eines ganzen Satzes erkannt werden kann, muss dies in einem zusätzlichen Schritt im Anschluss an die reine OCR-Erkennung erfolgen.
Ein Beispiel hierzu:

Raimund
26. August 2025 11:56
Autorenspezifische Erkennbarkeit und Themenkontext
Von der Unleserlichkeit sind aber nicht nur Wortendungen oder bestimmte untergeordnete Wortarten betroffen, sondern auch generell Verben und Nomen.
Das Besondere dabei ist, dass der Autor diese Worte selbst nur entziffern kann, weil er weiß in welchem Kontext – z.B. als Inhalt in einem Tagebuch zu einem bestimmten Zeitraum – er den Text geschrieben hat.
Dies kann verschiedene Ursachen haben:

Raimund
26. August 2025 11:57
Auch hier wird klar, dass das Projekt KI Sauklaue mit einer reinen OCR-Erkennung nicht weiterkommen kann und die Worte nur durch die Simulation eines Themenkontextes, z.B. einer Schlagwortliste, die Qualität der Handschriftenerkennung zusätzlich verbessern kann.
Auch hierzu ein praktisches Beispiel:

Raimund
26. August 2025 11:59
Aus diesem Aspekt wird auch deutlich, dass es Sinn machen kann, für einen Anwender je nach Themenkontext unterschiedliche Modelle zu erstellen. Dabei kann durchaus auf das gleiche mit der individuellen Handschrift trainierte TrOCR-Modell zurückgegriffen werden.
Aber andere Besonderheiten, wie z.B.
-
Hintergrund – worauf ist der Text geschrieben? -, oder eben
-
gesonderte Wortschätze, die sehr spezifisch zu dem Thema gehören und daher stark verkürzt oder vereinfacht aufgeschrieben werden – ich weiß doch, was ich meine - ,
können in einem eigenen Modell definiert werden.
Raimund
26. August 2025 19:30
Link zu KI Sauklaue - Einführung